diff --git a/.github/styles/Vocab/Timescale/accept.txt b/.github/styles/Vocab/Timescale/accept.txt
index 0f12e77ca5..cd7dfb7f28 100644
--- a/.github/styles/Vocab/Timescale/accept.txt
+++ b/.github/styles/Vocab/Timescale/accept.txt
@@ -2,6 +2,7 @@
Aiven
Alertmanager
API
+api
Anthropic
async
[Aa]utoscal(?:e|ing)
@@ -16,6 +17,7 @@ https?
BSD
[Cc]allouts?
COPY
+[Cc]opy
[Cc]lickstreams?
Cloudformation
Cloudwatch
diff --git a/.github/styles/config/vocabularies/Timescale/accept.txt b/.github/styles/config/vocabularies/Timescale/accept.txt
new file mode 100644
index 0000000000..cd7dfb7f28
--- /dev/null
+++ b/.github/styles/config/vocabularies/Timescale/accept.txt
@@ -0,0 +1,159 @@
+[Aa]ccessor
+Aiven
+Alertmanager
+API
+api
+Anthropic
+async
+[Aa]utoscal(?:e|ing)
+[Bb]ackfill(?:ing)?
+cron
+csv
+https?
+(?i)bigint
+[Bb]itemporal
+[Bb]lockchains?
+[Bb]oolean
+BSD
+[Cc]allouts?
+COPY
+[Cc]opy
+[Cc]lickstreams?
+Cloudformation
+Cloudwatch
+config
+[Cc]onstif(?:y|ied)
+[Cc]rypto
+[Cc]ryptocurrenc(?:y|ies)
+Datadog
+[Dd]efragment(:?s|ed)?
+Django
+distincts
+Docker
+[Dd]ownsampl(?:e|ing)
+erroring
+Ethereum
+[Ff]ailover
+[Ff]inalizers?
+[Ff]orex
+[Gg]apfill(?:ing)?
+[Gg]eospatial
+GitHub
+GNU
+Grafana
+GUC
+gsed
+gzip(?:ped)?
+Hasura
+HipChat
+[Hh]ostname
+href
+[Hh]yperloglog
+[Hh]yperfunctions?
+[Hh]ypertables?
+[Hh]ypershift
+img
+Indri
+[Ii]nserter
+[Ii]ntraday
+[Iin]validation
+ivfflat
+jpg
+JDBC
+JDK
+JSON
+Kafka
+Kaggle
+Kinesis
+[Ll]ambda
+LangChain
+LlamaIndex
+LLMs
+[Ll]ookups?
+loopback
+[Mm]atchers?
+[Mm]aterializer
+(?i)MST
+matplotlib
+[Mm]utators?
+Nagios
+[Nn]amespaces?
+[Nn]ullable
+Outflux
+[Pp]ageviews?
+[Pp]aralleliza(?:ble|tion)
+[Pp]athname
+Patroni
+Paulo
+[Pp]erformant
+pg_dump
+pg_restore
+[Pp]gvector
+[Pp]laintext
+Plotly
+pre
+POSIX
+PostgreSQL
+[Pp]ooler?
+Prometheus
+PromLens
+PromQL
+Promscale
+Protobuf
+psql
+[Qq]uantiles?
+qStudio
+RDS
+[Rr]edistribut(?:e|able)
+[Rr]eindex(?:ed)?
+reltuples
+[Rr]eusability
+[Rr]unbooks?
+[Ss]crollable
+Sequelize
+[Ss]ignups?
+[Ss]iloed
+(?i)smallint
+sed
+src
+[Ss]ubquer(?:y|ies)
+[Ss]ubsets?
+[Ss]upersets?
+[Tt]ablespaces?
+Telegraf
+Thanos
+Threema
+[Tt]iering
+[Tt]imevectors?
+Timescale(?:DB)?
+tobs
+[Tt]ransactionally
+tsdbadmin
+Uber
+[Uu]nary
+[Uu]ncomment
+[Uu]nencrypted
+Unix
+[Uu]nmaterialized
+[Uu]nregister
+[Uu]nthrottled?
+[Uu]ntier
+[Uu]pserts?
+[Rr]ebalanc(?:e|ing)
+[Rr]epos?
+[Rr]ollups?
+[Ss]erverless
+[Ss]hard(?:s|ing)?
+SkipScan
+(?i)timestamptz
+URLs?
+URIs?
+UUID
+versionContent
+[Vv]irtualenv
+WAL
+[Ww]ebsockets?
+Worldmap
+www
+Zabbix
+Zipkin
diff --git a/_partials/_add-data-blockchain.md b/_partials/_add-data-blockchain.md
index 924f31d044..5e359ee738 100644
--- a/_partials/_add-data-blockchain.md
+++ b/_partials/_add-data-blockchain.md
@@ -1,16 +1,14 @@
## Load financial data
-This tutorial uses Bitcoin transactions from the past five days.
-
-## Ingest the dataset
+The dataset contains around 1.5 million Bitcoin transactions, the trades for five days. It includes
+information about each transaction, along with the value in [satoshi][satoshi-def]. It also states if a
+trade is a [coinbase][coinbase-def] transaction, and the reward a coin miner receives for mining the coin.
To ingest data into the tables that you created, you need to download the
dataset and copy the data to your database.
-### Ingesting the dataset
-
1. Download the `bitcoin_sample.zip` file. The file contains a `.csv`
file that contains Bitcoin transactions for the past five days. Download:
@@ -37,3 +35,6 @@ dataset and copy the data to your database.
resources.
+
+[satoshi-def]: https://www.pcmag.com/encyclopedia/term/satoshi
+[coinbase-def]: https://www.pcmag.com/encyclopedia/term/coinbase-transaction
diff --git a/_partials/_add-data-energy.md b/_partials/_add-data-energy.md
index a10dc6b3e6..c42420ae13 100644
--- a/_partials/_add-data-energy.md
+++ b/_partials/_add-data-energy.md
@@ -5,8 +5,6 @@ into the `metrics` hypertable.
-### Loading energy consumption data
-
This is a large dataset, so it might take a long time, depending on your network
connection.
diff --git a/_partials/_add-data-nyctaxis.md b/_partials/_add-data-nyctaxis.md
index 60b9f5231a..8f5d1313e6 100644
--- a/_partials/_add-data-nyctaxis.md
+++ b/_partials/_add-data-nyctaxis.md
@@ -5,8 +5,6 @@ When you have your database set up, you can load the taxi trip data into the
-### Loading trip data
-
This is a large dataset, so it might take a long time, depending on your network
connection.
diff --git a/_partials/_add-data-twelvedata-crypto.md b/_partials/_add-data-twelvedata-crypto.md
index 5e35ecb48a..3021b352d4 100644
--- a/_partials/_add-data-twelvedata-crypto.md
+++ b/_partials/_add-data-twelvedata-crypto.md
@@ -1,29 +1,29 @@
## Load financial data
This tutorial uses real-time cryptocurrency data, also known as tick data, from
-[Twelve Data][twelve-data]. A direct download link is provided below.
+[Twelve Data][twelve-data]. To ingest data into the tables that you created, you need to
+download the dataset, then upload the data to your $SERVICE_LONG.
-### Ingest the dataset
+
-To ingest data into the tables that you created, you need to download the
-dataset and copy the data to your database.
-
+1. Unzip [crypto_sample.zip](https://assets.timescale.com/docs/downloads/candlestick/crypto_sample.zip) to a ``.
-#### Ingesting the dataset
+ This test dataset contains second-by-second trade data for the most-traded crypto-assets
+ and a regular table of asset symbols and company names.
-1. Download the `crypto_sample.zip` file. The file contains two `.csv`
- files; one with company information, and one with real-time stock trades for
- the past month. Download:
- [crypto_sample.zip](https://assets.timescale.com/docs/downloads/candlestick/crypto_sample.zip)
-
+ To import up to 100GB of data directly from your current PostgreSQL based database,
+ [migrate with downtime][migrate-with-downtime] using native PostgreSQL tooling. To seamlessly import 100GB-10TB+
+ of data, use the [live migration][migrate-live] tooling supplied by $COMPANY. To add data from non-PostgreSQL
+ data sources, see [Import and ingest data][data-ingest].
-1. In a new terminal window, run this command to unzip the `.csv` files:
- ```bash
- unzip crypto_sample.zip
- ```
+
+1. In Terminal, navigate to `` and connect to your $SERVICE_SHORT.
+ ```bash
+ psql -d "postgres://:@:/"
+ ```
+ The connection information for a $SERVICE_SHORT is available in the file you downloaded when you created it.
1. At the `psql` prompt, use the `COPY` command to transfer data into your
Timescale instance. If the `.csv` files aren't in your current directory,
@@ -44,3 +44,6 @@ dataset and copy the data to your database.
[twelve-data]: https://twelvedata.com/
+[migrate-with-downtime]: /migrate/:currentVersion:/pg-dump-and-restore/
+[migrate-live]: /migrate/:currentVersion:/live-migration/
+[data-ingest]: /use-timescale/:currentVersion:/ingest-data/
diff --git a/_partials/_add-data-twelvedata-stocks.md b/_partials/_add-data-twelvedata-stocks.md
index 7be487e717..fb3a13b13d 100644
--- a/_partials/_add-data-twelvedata-stocks.md
+++ b/_partials/_add-data-twelvedata-stocks.md
@@ -3,15 +3,11 @@
This tutorial uses real-time stock trade data, also known as tick data, from
[Twelve Data][twelve-data]. A direct download link is provided below.
-## Ingest the dataset
-
To ingest data into the tables that you created, you need to download the
dataset and copy the data to your database.
-#### Ingesting the dataset
-
1. Download the `real_time_stock_data.zip` file. The file contains two `.csv`
files; one with company information, and one with real-time stock trades for
the past month. Download:
diff --git a/_partials/_caggs-intro.md b/_partials/_caggs-intro.md
index 220c6053fc..1215a8f69f 100644
--- a/_partials/_caggs-intro.md
+++ b/_partials/_caggs-intro.md
@@ -1,12 +1,12 @@
-Time-series data usually grows very quickly. And that means that aggregating the
-data into useful summaries can become very slow. Continuous aggregates makes
-aggregating data lightning fast.
+In modern applications, data usually grows very quickly. This means that aggregating
+it into useful summaries can become very slow. $CLOUD_LONG continuous aggregates make
+aggregating data lightning fast, accurate, and easy.
If you are collecting data very frequently, you might want to aggregate your
-data into minutes or hours instead. For example, if you have a table of
-temperature readings taken every second, you can find the average temperature
+data into minutes or hours instead. For example, if an IoT device takes
+temperature readings every second, you might want to find the average temperature
for each hour. Every time you run this query, the database needs to scan the
-entire table and recalculate the average every time.
+entire table and recalculate the average.
Continuous aggregates are a kind of hypertable that is refreshed automatically
in the background as new data is added, or old data is modified. Changes to your
@@ -21,10 +21,10 @@ means that you can get on with working your data instead of maintaining your
database.
Because continuous aggregates are based on hypertables, you can query them in
-exactly the same way as your other tables, and enable [Hypercore][hypercore]
-or [tiered storage][data-tiering] on your continuous aggregates. You can even
+exactly the same way as your other tables, and enable [compression][compression]
+or [tiered storage][data-tiering] on them. You can even
create
-[continuous aggregates on top of your continuous aggregates][hierarchical-caggs].
+[continuous aggregates on top of your continuous aggregates][hierarchical-caggs] - for an even more fine-tuned aggregation.
By default, querying continuous aggregates provides you with real-time data.
Pre-aggregated data from the materialized view is combined with recent data that
diff --git a/_partials/_cloud-create-connect-tutorials.md b/_partials/_cloud-create-connect-tutorials.md
index 55bae061e2..a96cbf3892 100644
--- a/_partials/_cloud-create-connect-tutorials.md
+++ b/_partials/_cloud-create-connect-tutorials.md
@@ -6,9 +6,7 @@ command-line utility. If you've used PostgreSQL before, you might already have
-### Create a Timescale service and connect to the service
-
-1. In the [Timescale portal][timescale-portal], click `Create service`.
+1. In the [$CONSOLE][timescale-portal], click `Create service`.
1. Click `Download the cheatsheet` to download an SQL file that contains the
login details for your new service. You can also copy the details directly
from this page. When you have copied your password,
diff --git a/_partials/_create-hypertable-blockchain.md b/_partials/_create-hypertable-blockchain.md
index 84761f1e02..9d277e6130 100644
--- a/_partials/_create-hypertable-blockchain.md
+++ b/_partials/_create-hypertable-blockchain.md
@@ -1,5 +1,5 @@
-## Create a hypertable
+## Optimize time-series data in hypertables
Hypertables are the core of Timescale. Hypertables enable Timescale to work
efficiently with time-series data. Because Timescale is PostgreSQL, all the
@@ -9,8 +9,6 @@ with Timescale tables similar to standard PostgreSQL.
-### Creating a hypertable
-
1. Create a standard PostgreSQL table to store the Bitcoin blockchain data
using `CREATE TABLE`:
diff --git a/_partials/_create-hypertable-energy.md b/_partials/_create-hypertable-energy.md
index 235a90d788..ff75bf552e 100644
--- a/_partials/_create-hypertable-energy.md
+++ b/_partials/_create-hypertable-energy.md
@@ -1,4 +1,4 @@
-## Create a hypertable
+## Optimize time-series data in hypertables
Hypertables are the core of Timescale. Hypertables enable Timescale to work
efficiently with time-series data. Because Timescale is PostgreSQL, all the
@@ -8,8 +8,6 @@ with Timescale tables similar to standard PostgreSQL.
-### Creating a hypertable
-
1. Create a standard PostgreSQL table to store the energy consumption data
using `CREATE TABLE`:
diff --git a/_partials/_create-hypertable-nyctaxis.md b/_partials/_create-hypertable-nyctaxis.md
index b41a579de4..3400e849b6 100644
--- a/_partials/_create-hypertable-nyctaxis.md
+++ b/_partials/_create-hypertable-nyctaxis.md
@@ -1,17 +1,16 @@
-## Create a hypertable
+## Optimize time-series data in hypertables
-Hypertables are the core of Timescale. Hypertables enable Timescale to work
-efficiently with time-series data. Because Timescale is PostgreSQL, all the
-standard PostgreSQL tables, indexes, stored procedures and other objects can be
-created alongside your Timescale hypertables. This makes creating and working
-with Timescale tables similar to standard PostgreSQL.
+Time-series data represents how a system, process, or behavior changes over time. [Hypertables][hypertables-section]
+are PostgreSQL tables that help you improve insert and query performance by automatically partitioning your data by
+time. Each hypertable is made up of child tables called chunks. Each chunk is assigned a range of time, and only
+contains data from that range.
-
+Hypertables exist alongside regular PostgreSQL tables. You use regular PostgreSQL tables for relational data, and
+interact with hypertables and regular PostgreSQL tables in the same way.
-### Creating a hypertable
+
-1. Create a standard PostgreSQL table to store the taxi trip data
- using `CREATE TABLE`:
+1. **Create a standard PostgreSQL table to store the taxi trip data**
```sql
CREATE TABLE "rides"(
@@ -36,7 +35,8 @@ with Timescale tables similar to standard PostgreSQL.
);
```
-1. Convert the standard table into a hypertable partitioned on the `time`
+1. **Convert the standard table into a hypertable**
+ Partitioned on the `time`
column using the `create_hypertable()` function provided by Timescale. You
must provide the name of the table and the column in that table that holds
the timestamp data to use for partitioning:
@@ -69,8 +69,6 @@ there are two other tables of data, called `payment_types` and `rates`.
-### Creating standard PostgreSQL tables
-
1. Add a table to store the payment types data:
```sql
@@ -117,3 +115,6 @@ the `psql` command line. You should see this:
public | rides | table | tsdbadmin
(3 rows)
```
+
+
+[hypertables-section]: /use-timescale/:currentVersion:/hypertables/
diff --git a/_partials/_create-hypertable-twelvedata-crypto.md b/_partials/_create-hypertable-twelvedata-crypto.md
index 4412295ea7..05739038d2 100644
--- a/_partials/_create-hypertable-twelvedata-crypto.md
+++ b/_partials/_create-hypertable-twelvedata-crypto.md
@@ -1,18 +1,22 @@
-## Create a hypertable
+## Optimize time-series data in a hypertable
-Hypertables are the core of Timescale. Hypertables enable Timescale to work
-efficiently with time-series data. Because Timescale is PostgreSQL, all the
-standard PostgreSQL tables, indexes, stored procedures, and other objects can be
-created alongside your Timescale hypertables. This makes creating and working
-with Timescale tables similar to standard PostgreSQL.
+Hypertables are the core of $TIMESCALE_DB, they enable $CLOUD_LONG to work
+efficiently with time-series data. Hypertables are PostgreSQL tables that automatically
+partition your time-series data by time. When you run a query, $CLOUD_LONG identifies the
+correct partition and runs the query on it, instead of going through the entire table.
+
+Because $TIMESCALE_DB is 100% PostgreSQL, you can create standard PostgreSQL tables, indexes, stored
+procedures, and other objects alongside your Timescale hypertables. This makes creating and working
+with hypertables similar to standard PostgreSQL.
-### Creating a hypertable
+1. Connect to your $SERVICE_LONG.
+
+ In [$CONSOLE][services-portal] open an [SQL editor][in-console-editors]. You can also connect to your service using [psql][connect-using-psql].
-1. Create a standard PostgreSQL table to store the real-time cryptocurrency data
- using `CREATE TABLE`:
+1. Create a standard PostgreSQL table to store the real-time cryptocurrency data:
```sql
CREATE TABLE crypto_ticks (
@@ -32,23 +36,16 @@ with Timescale tables similar to standard PostgreSQL.
SELECT create_hypertable('crypto_ticks', by_range('time'));
```
-
- The `by_range` dimension builder is an addition to TimescaleDB 2.13.
-
-
-## Create standard PostgreSQL tables for relational data
+## Create a standard PostgreSQL table for relational data
-When you have other relational data that enhances your time-series data, you can
-create standard PostgreSQL tables just as you would normally. For this dataset,
-there is one other table of data called `crypto_assets`.
+When you have relational data that enhances your time-series data, store that data in
+standard PostgreSQL relational tables.
-### Creating standard PostgreSQL tables
-
-1. Add a table to store the company name and symbol for the stock trade data:
+1. Add a table to store the asset symbol and name in a relational table:
```sql
CREATE TABLE crypto_assets (
@@ -57,7 +54,11 @@ there is one other table of data called `crypto_assets`.
);
```
-1. You now have two tables within your Timescale database. One hypertable
- named `crypto_ticks`, and one normal PostgreSQL table named `crypto_assets`.
-
+
+You now have two tables within your $SERVICE_LONG. A hypertable named `crypto_ticks`, and a normal
+PostgreSQL table named `crypto_assets`.
+
+[in-console-editors]: /getting-started/:currentVersion:/run-queries-from-console/
+[services-portal]: https://console.cloud.timescale.com/dashboard/services
+[connect-using-psql]: /use-timescale/:currentVersion:/integrations/query-admin/psql#connect-to-your-service
diff --git a/_partials/_create-hypertable-twelvedata-stocks.md b/_partials/_create-hypertable-twelvedata-stocks.md
index 85727a9fdc..6e06273e9b 100644
--- a/_partials/_create-hypertable-twelvedata-stocks.md
+++ b/_partials/_create-hypertable-twelvedata-stocks.md
@@ -1,5 +1,5 @@
-## Create a hypertable
+## Optimize time-series data in hypertables
Hypertables are the core of Timescale. Hypertables enable Timescale to work
efficiently with time-series data. Because Timescale is PostgreSQL, all the
@@ -9,8 +9,6 @@ with Timescale tables similar to standard PostgreSQL.
-### Creating a hypertable
-
1. Create a standard PostgreSQL table to store the real-time stock trade data
using `CREATE TABLE`:
diff --git a/_partials/_financial-industry-data-analysis.md b/_partials/_financial-industry-data-analysis.md
new file mode 100644
index 0000000000..bfd6293928
--- /dev/null
+++ b/_partials/_financial-industry-data-analysis.md
@@ -0,0 +1 @@
+The financial industry is extremely data-heavy and relies on real-time and historical data for decision-making, risk assessment, fraud detection, and market analysis. Timescale simplifies management of these large volumes of data, while also providing you with meaningful analytical insights and optimizing storage costs.
\ No newline at end of file
diff --git a/_partials/_grafana-connect.md b/_partials/_grafana-connect.md
index fdc3619001..0bce6cd58b 100644
--- a/_partials/_grafana-connect.md
+++ b/_partials/_grafana-connect.md
@@ -1,14 +1,6 @@
-## Prerequisites
+## Connect Grafana to $CLOUD_LONG
-import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
-
-
-
-* Install [self-managed Grafana][grafana-self-managed] or sign up for [Grafana Cloud][grafana-cloud].
-
-## Add your $SERVICE_SHORT as a data source
-
-To connect the data in your $SERVICE_SHORT to Grafana:
+To visualize the results of your queries, enable Grafana to read the data in your $SERVICE_SHORT:
@@ -21,15 +13,16 @@ To connect the data in your $SERVICE_SHORT to Grafana:
1. Open `Connections` > `Data sources`, then click `Add new data source`.
1. Select `PostgreSQL` from the list.
1. Configure the connection:
- - `Host URL`, `Username`, `Password`, and `Database`: configure using your [connection details][connection-info].
- - `Database name`: provide the name for your dataset.
- - `TLS/SSL Mode`: select `require`.
- - `PostgreSQL options`: enable `TimescaleDB`.
- - Leave the default setting for all other fields.
-
- 1. **Click `Save & test`**
+ - `Host URL`, `Database name`, `Username`, and `Password`
+
+ Configure using your [connection details][connection-info]. `Host URL` is in the format `:`.
+ - `TLS/SSL Mode`: select `require`.
+ - `PostgreSQL options`: enable `TimescaleDB`.
+ - Leave the default setting for all other fields.
+
+ 1. Click `Save & test`.
- Grafana checks that your details are set correctly.
+ Grafana checks that your details are set correctly.
diff --git a/_partials/_graphing-ohlcv-data.md b/_partials/_graphing-ohlcv-data.md
index 2e7a51d53b..272ac3d156 100644
--- a/_partials/_graphing-ohlcv-data.md
+++ b/_partials/_graphing-ohlcv-data.md
@@ -9,12 +9,12 @@ up to connect to your TimescaleDB database.
### Graphing OHLCV data
1. Ensure you have Grafana installed, and you are using the TimescaleDB
- database that contains the Twelve Data stocks dataset set up as a
+ database that contains the Twelve Data dataset set up as a
data source.
1. In Grafana, from the `Dashboards` menu, click `New Dashboard`. In the
`New Dashboard` page, click `Add a new panel`.
1. In the `Visualizations` menu in the top right corner, select `Candlestick`
- from the list. Ensure you have set the Twelve Data stocks dataset as
+ from the list. Ensure you have set the Twelve Data dataset as
your data source.
1. Click `Edit SQL` and paste in the query you used to get the OHLCV values.
1. In the `Format as` section, select `Table`.
diff --git a/_partials/_high-availability-setup.md b/_partials/_high-availability-setup.md
new file mode 100644
index 0000000000..5eb9eb15d1
--- /dev/null
+++ b/_partials/_high-availability-setup.md
@@ -0,0 +1,13 @@
+
+
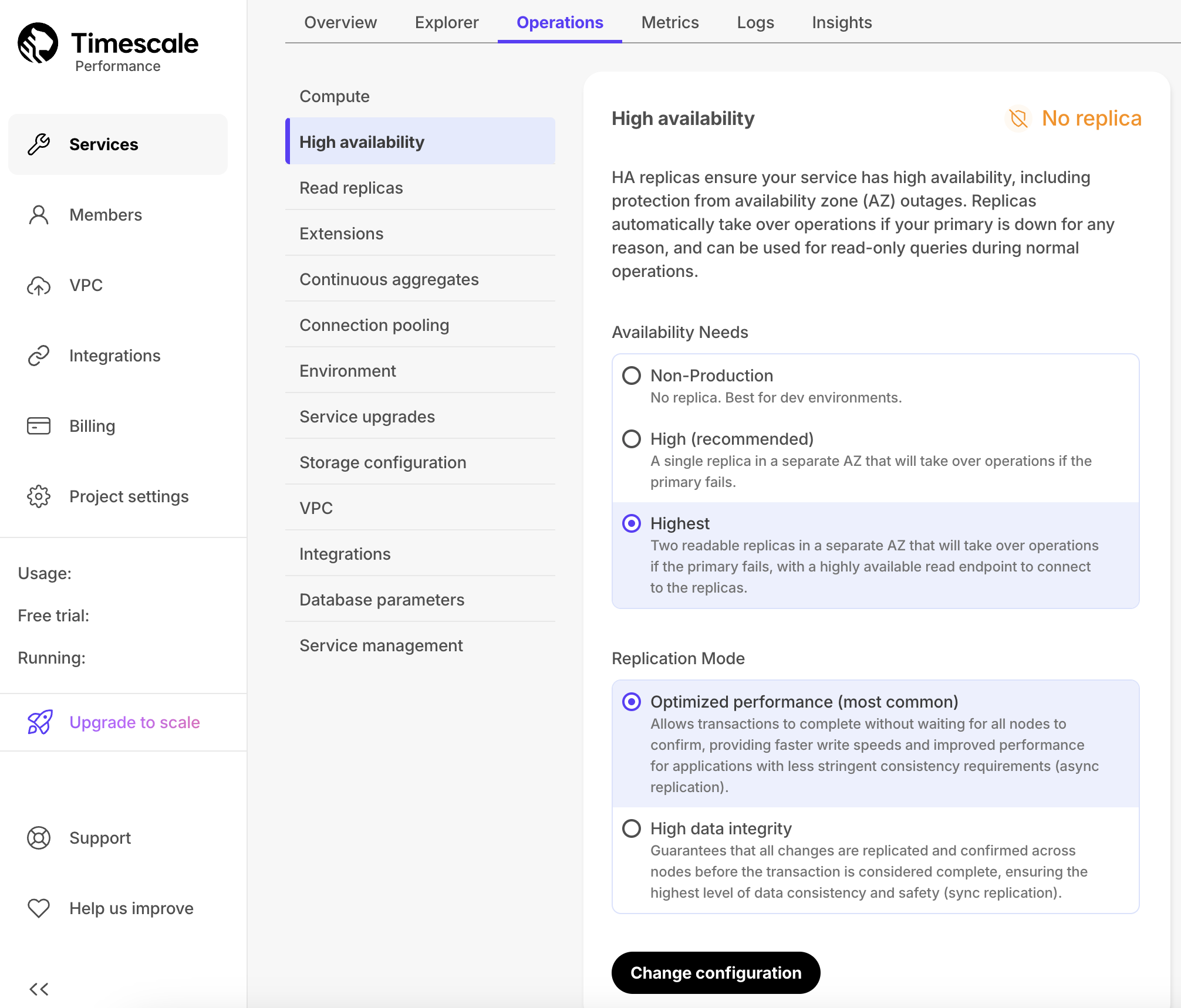
+1. In [Timescale Console][cloud-login], select the service to enable replication for.
+1. Click `Operations`, then select `High availability`.
+1. Choose your replication strategy, then click `Change configuration`.
+
+ 
+
+1. In `Change high availability configuration`, click `Change config`.
+
+
+
+[cloud-login]: https://console.cloud.timescale.com
diff --git a/_partials/_hypercore_policy_workflow.md b/_partials/_hypercore_policy_workflow.md
index c980d6907d..1d762ff278 100644
--- a/_partials/_hypercore_policy_workflow.md
+++ b/_partials/_hypercore_policy_workflow.md
@@ -1,5 +1,7 @@
import EarlyAccess from "versionContent/_partials/_early_access.mdx";
+
+
1. **Connect to your $SERVICE_LONG**
In [$CONSOLE][services-portal] open an [SQL editor][in-console-editors]. You can also connect to your service using [psql][connect-using-psql].
@@ -79,6 +81,7 @@ import EarlyAccess from "versionContent/_partials/_early_access.mdx";
```
See [alter_table_hypercore][alter_table_hypercore].
+
[job]: /api/:currentVersion:/actions/add_job/
[alter_table_hypercore]: /api/:currentVersion:/hypercore/alter_table/
diff --git a/_partials/_hypertables-intro.md b/_partials/_hypertables-intro.md
index 5b3d450076..fb2d811fc3 100644
--- a/_partials/_hypertables-intro.md
+++ b/_partials/_hypertables-intro.md
@@ -1,15 +1,12 @@
-Hypertables are PostgreSQL tables that automatically partition your data by
-time. You interact with hypertables in the same way as regular PostgreSQL
-tables, but with extra features that makes managing your time-series data much
-easier.
-
-In Timescale, hypertables exist alongside regular PostgreSQL tables. Use
-hypertables to store time-series data. This gives you improved insert and query
-performance, and access to useful time-series features. Use regular PostgreSQL
-tables for other relational data.
-
-With hypertables, Timescale makes it easy to improve insert and query
-performance by partitioning time-series data on its time parameter. Behind the
-scenes, the database performs the work of setting up and maintaining the
-hypertable's partitions. Meanwhile, you insert and query your data as if it all
-lives in a single, regular PostgreSQL table.
+$CLOUD_LONG supercharges your real-time analytics by letting you run complex queries continuously, with near-zero latency. Under the hood, this is achieved by using hypertables - PostgreSQL tables that automatically partition your time-series data by time and optionally by space. When you run a query, $CLOUD_LONG identifies the correct partition and runs the query on it, instead of going through the entire table.
+
+Hypertables offer a range of other features, such as [skipping partitions][chunk-skipping] or running [hyperfunctions][hyperfunctions], that boost the performance of your analytical queries even more.
+
+To top it all, there is no added complexity - you interact with hypertables in the same way as you would with regular PostgreSQL tables. All the optimization magic happens behind the scenes.
+
+[chunk-skipping]: /use-timescale/:currentVersion:/hypertables/improve-query-performance/
+[hyperfunctions]: /use-timescale/:currentVersion:/hyperfunctions/
+
+
+
+
diff --git a/_partials/_import-data-iot.md b/_partials/_import-data-iot.md
new file mode 100644
index 0000000000..61a977f004
--- /dev/null
+++ b/_partials/_import-data-iot.md
@@ -0,0 +1,86 @@
+Time-series data represents how a system, process, or behavior changes over time. [Hypertables][hypertables-section]
+are PostgreSQL tables that help you improve insert and query performance by automatically partition your data by
+time, speeding up queries for real-time analytics and other challenging workloads. Each hypertable is made up of child
+tables called chunks. Each chunk is assigned a range of time, and only contains data from that range.
+
+
+
+1. **Import time-series data into a hypertable**
+
+ 1. Unzip [metrics.csv.gz](https://assets.timescale.com/docs/downloads/metrics.csv.gz) to a ``.
+
+ This test dataset contains energy consumption data.
+
+ To import up to 100GB of data directly from your current PostgreSQL based database,
+ [migrate with downtime][migrate-with-downtime] using native PostgreSQL tooling. To seamlessly import 100GB-10TB+
+ of data, use the [live migration][migrate-live] tooling supplied by $COMPANY. To add data from non-PostgreSQL
+ data sources, see [Import and ingest data][data-ingest].
+
+ 1. In Terminal, navigate to `` and update the following string with [your connection details][connection-info]
+ to connect to your $SERVICE_SHORT.
+
+ ```bash
+ psql -d "postgres://:@:/?sslmode=require"
+ ```
+
+ 1. Create tables to import time-series data:
+
+ 1. In your sql client, create a normal PostgreSQL table:
+
+ ```sql
+ CREATE TABLE "metrics"(
+ created timestamp with time zone default now() not null,
+ type_id integer not null,
+ value double precision not null
+ );
+ ```
+
+ 1. Convert `metrics` to a hypertable and partitioned on time:
+ ```sql
+ SELECT create_hypertable('metrics', by_range('created'));
+ ```
+ To more fully understand how hypertables work, and how to optimize them for performance by
+ tuning chunk intervals and enabling chunk skipping, see [the hypertables documentation][hypertables-section].
+
+ 1. Upload the dataset to your $SERVICE_SHORT
+ ```sql
+ \COPY metrics FROM metrics.csv CSV;
+ ```
+ To more fully understand how hypertables work, and how to optimize them for performance by
+ tuning chunk intervals and enabling chunk skipping, see [the hypertables documentation][hypertables-section].
+
+1. **Have a quick look at your data**
+
+ You query hypertables in exactly the same way as you would a relational PostgreSQL table.
+ Use one of the following SQL editors to run a query and see the data you uploaded:
+ - **Data mode**: write queries, visualize data, and share your results in [$CONSOLE][portal-data-mode] for all your $SERVICE_LONGs.
+ - **SQL editor**: write, fix, and organize SQL faster and more accurately in [$CONSOLE][portal-ops-mode] for a $SERVICE_LONG.
+ - **psql**: easily run queries on your $SERVICE_LONGs or self-hosted TimescaleDB deployment from Terminal.
+
+ ```sql
+ SELECT time_bucket('1 day', created, 'Europe/Berlin') AS "time",
+ round((last(value, created) - first(value, created)) * 100.) / 100. AS value
+ FROM metrics
+ WHERE type_id = 5
+ GROUP BY 1;
+ ```
+
+ On this amount of data, this query on data in the rowstore takes about 3.6 seconds. You see something like:
+
+ | Time | value |
+ |------------------------------|-------|
+ | 2023-05-29 22:00:00+00 | 23.1 |
+ | 2023-05-28 22:00:00+00 | 19.5 |
+ | 2023-05-30 22:00:00+00 | 25 |
+ | 2023-05-31 22:00:00+00 | 8.1 |
+
+
+
+[hypertables-section]: /use-timescale/:currentVersion:/hypertables/
+[portal-ops-mode]: https://console.cloud.timescale.com/dashboard/services
+[portal-data-mode]: https://console.cloud.timescale.com/dashboard/services?popsql
+[connection-info]: /use-timescale/:currentVersion:/integrations/find-connection-details/
+[migrate-with-downtime]: /migrate/:currentVersion:/pg-dump-and-restore/
+[migrate-live]: /migrate/:currentVersion:/live-migration/
+[data-ingest]: /use-timescale/:currentVersion:/ingest-data/
+
diff --git a/_partials/_import-data-nyc-taxis.md b/_partials/_import-data-nyc-taxis.md
new file mode 100644
index 0000000000..dca210b2cf
--- /dev/null
+++ b/_partials/_import-data-nyc-taxis.md
@@ -0,0 +1,168 @@
+Time-series data represents how a system, process, or behavior changes over time. [Hypertables][hypertables-section]
+are PostgreSQL tables that help you improve insert and query performance by automatically partition your data by
+time, speeding up queries for real-time analytics and other challenging workloads. Each hypertable is made up of child
+tables called chunks. Each chunk is assigned a range of time, and only contains data from that range.
+
+
+
+1. **Import time-series data into a hypertable**
+
+ 1. Unzip [nyc_data.tar.gz](https://assets.timescale.com/docs/downloads/nyc_data.tar.gz) to a ``.
+
+ This test dataset contains historical data from New York's yellow taxi network.
+
+ To import up to 100GB of data directly from your current PostgreSQL based database,
+ [migrate with downtime][migrate-with-downtime] using native PostgreSQL tooling. To seamlessly import 100GB-10TB+
+ of data, use the [live migration][migrate-live] tooling supplied by $COMPANY. To add data from non-PostgreSQL
+ data sources, see [Import and ingest data][data-ingest].
+
+ 1. In Terminal, navigate to `` and update the following string with [your connection details][connection-info]
+ to connect to your $SERVICE_SHORT.
+
+ ```bash
+ psql -d "postgres://:@:/?sslmode=require"
+ ```
+
+ 1. Create tables to import time-series data:
+
+ 1. In your sql client, create a normal PostgreSQL table:
+
+ ```sql
+ CREATE TABLE "rides"(
+ vendor_id TEXT,
+ pickup_datetime TIMESTAMP WITHOUT TIME ZONE NOT NULL,
+ dropoff_datetime TIMESTAMP WITHOUT TIME ZONE NOT NULL,
+ passenger_count NUMERIC,
+ trip_distance NUMERIC,
+ pickup_longitude NUMERIC,
+ pickup_latitude NUMERIC,
+ rate_code INTEGER,
+ dropoff_longitude NUMERIC,
+ dropoff_latitude NUMERIC,
+ payment_type INTEGER,
+ fare_amount NUMERIC,
+ extra NUMERIC,
+ mta_tax NUMERIC,
+ tip_amount NUMERIC,
+ tolls_amount NUMERIC,
+ improvement_surcharge NUMERIC,
+ total_amount NUMERIC
+ );
+ ```
+
+ 1. Convert `rides` to a hypertable and partitioned on time:
+ ```sql
+ SELECT create_hypertable('rides', by_range('pickup_datetime'), create_default_indexes=>FALSE);
+ SELECT add_dimension('rides', by_hash('payment_type', 2));
+ ```
+ To more fully understand how hypertables work, and how to optimize them for performance by
+ tuning chunk intervals and enabling chunk skipping, see [the hypertables documentation][hypertables-section].
+
+ 1. Create an index to support efficient queries by vendor, rate code, and passenger count:
+ ```sql
+ CREATE INDEX ON rides (vendor_id, pickup_datetime DESC);
+ CREATE INDEX ON rides (rate_code, pickup_datetime DESC);
+ CREATE INDEX ON rides (passenger_count, pickup_datetime DESC);
+ ```
+
+ 1. Create tables for relational data:
+
+ 1. Add a table to store the payment types data:
+
+ ```sql
+ CREATE TABLE IF NOT EXISTS "payment_types"(
+ payment_type INTEGER,
+ description TEXT
+ );
+ INSERT INTO payment_types(payment_type, description) VALUES
+ (1, 'credit card'),
+ (2, 'cash'),
+ (3, 'no charge'),
+ (4, 'dispute'),
+ (5, 'unknown'),
+ (6, 'voided trip');
+ ```
+
+ 1. Add a table to store the rates data:
+
+ ```sql
+ CREATE TABLE IF NOT EXISTS "rates"(
+ rate_code INTEGER,
+ description TEXT
+ );
+ INSERT INTO rates(rate_code, description) VALUES
+ (1, 'standard rate'),
+ (2, 'JFK'),
+ (3, 'Newark'),
+ (4, 'Nassau or Westchester'),
+ (5, 'negotiated fare'),
+ (6, 'group ride');
+ ```
+
+ 1. Upload the dataset to your $SERVICE_SHORT
+ ```sql
+ \COPY rides FROM nyc_data_rides.csv CSV;
+ ```
+ To more fully understand how hypertables work, and how to optimize them for performance by
+ tuning chunk intervals and enabling chunk skipping, see [the hypertables documentation][hypertables-section].
+
+1. **Have a quick look at your data**
+
+ You query hypertables in exactly the same way as you would a relational PostgreSQL table.
+ Use one of the following SQL editors to run a query and see the data you uploaded:
+ - **Data mode**: write queries, visualize data, and share your results in [$CONSOLE][portal-data-mode] for all your $SERVICE_LONGs.
+ - **SQL editor**: write, fix, and organize SQL faster and more accurately in [$CONSOLE][portal-ops-mode] for a $SERVICE_LONG.
+ - **psql**: easily run queries on your $SERVICE_LONGs or self-hosted TimescaleDB deployment from Terminal.
+
+ For example:
+ - Display the number of rides for each fare type:
+ ```sql
+ SELECT rate_code, COUNT(vendor_id) AS num_trips
+ FROM rides
+ WHERE pickup_datetime < '2016-01-08'
+ GROUP BY rate_code
+ ORDER BY rate_code;
+ ```
+ This simple query runs in 3 seconds. You see something like:
+
+ | rate_code | num_trips |
+ |-----------------|-----------|
+ |1 | 2266401|
+ |2 | 54832|
+ |3 | 4126|
+ |4 | 967|
+ |5 | 7193|
+ |6 | 17|
+ |99 | 42|
+
+ - To select all rides taken in the first week of January 2016, and return the total number of trips taken for each rate code:
+ ```sql
+ SELECT rates.description, COUNT(vendor_id) AS num_trips
+ FROM rides
+ JOIN rates ON rides.rate_code = rates.rate_code
+ WHERE pickup_datetime < '2016-01-08'
+ GROUP BY rates.description
+ ORDER BY LOWER(rates.description);
+ ```
+ On this large amount of data, this analytical query on data in the rowstore takes about 59 seconds. You see something like:
+
+ | description | num_trips |
+ |-----------------|-----------|
+ | group ride | 17 |
+ | JFK | 54832 |
+ | Nassau or Westchester | 967 |
+ | negotiated fare | 7193 |
+ | Newark | 4126 |
+ | standard rate | 2266401 |
+
+
+
+
+[hypertables-section]: /use-timescale/:currentVersion:/hypertables/
+[portal-ops-mode]: https://console.cloud.timescale.com/dashboard/services
+[portal-data-mode]: https://console.cloud.timescale.com/dashboard/services?popsql
+[connection-info]: /use-timescale/:currentVersion:/integrations/find-connection-details/
+[migrate-with-downtime]: /migrate/:currentVersion:/pg-dump-and-restore/
+[migrate-live]: /migrate/:currentVersion:/live-migration/
+[data-ingest]: /use-timescale/:currentVersion:/ingest-data/
+
diff --git a/_partials/_integration-prereqs-cloud-only.md b/_partials/_integration-prereqs-cloud-only.md
index b46e842697..0b21e814f9 100644
--- a/_partials/_integration-prereqs-cloud-only.md
+++ b/_partials/_integration-prereqs-cloud-only.md
@@ -1,5 +1,10 @@
-To follow the procedure on this page, you need to:
-* Create a target [$SERVICE_LONG][create-service].
+To follow the steps on this page:
+
+* Create a target [$SERVICE_LONG][create-service] with time-series and analytics enabled.
+
+ You need your [connection details][connection-info].
+
[create-service]: /getting-started/:currentVersion:/services/
+[connection-info]: /use-timescale/:currentVersion:/integrations/find-connection-details/
diff --git a/_partials/_integration-prereqs.md b/_partials/_integration-prereqs.md
index 26a70caf25..26d94388b6 100644
--- a/_partials/_integration-prereqs.md
+++ b/_partials/_integration-prereqs.md
@@ -1,10 +1,11 @@
-To follow the procedure on this page, you need to:
+To follow the steps on this page:
-* Create a target [$SERVICE_LONG][create-service]
+* Create a target [$SERVICE_LONG][create-service] with time-series and analytics enabled.
- You need your [connection details][connection-info] to follow the steps in this page. This procedure also
+ You need [your connection details][connection-info]. This procedure also
works for [self-hosted $TIMESCALE_DB][enable-timescaledb].
+
[create-service]: /getting-started/:currentVersion:/services/
[enable-timescaledb]: /self-hosted/:currentVersion:/install/
[connection-info]: /use-timescale/:currentVersion:/integrations/find-connection-details/
diff --git a/_partials/_usage-based-storage-intro.md b/_partials/_usage-based-storage-intro.md
index 0054c6fcc0..3ef590afc9 100644
--- a/_partials/_usage-based-storage-intro.md
+++ b/_partials/_usage-based-storage-intro.md
@@ -1,7 +1,7 @@
$CLOUD_LONG charges are based on the amount of storage you use. You don't pay for
fixed storage size, and you don't need to worry about scaling disk size as your
-data grows; We handle it all for you. To reduce your data costs further,
-use [Hypercore][hypercore], a [data retention policy][data-retention], and
+data grows - we handle it all for you. To reduce your data costs further,
+combine [hypercore][hypercore], a [data retention policy][data-retention], and
[tiered storage][data-tiering].
[hypercore]: /api/:currentVersion:/hypercore/
diff --git a/_partials/_use-case-iot-create-cagg.md b/_partials/_use-case-iot-create-cagg.md
new file mode 100644
index 0000000000..7a8f13940f
--- /dev/null
+++ b/_partials/_use-case-iot-create-cagg.md
@@ -0,0 +1,87 @@
+1. **Monitor energy consumption on a day-to-day basis**
+
+ 1. Create a continuous aggregate `kwh_day_by_day` for energy consumption:
+
+ ```sql
+ CREATE MATERIALIZED VIEW kwh_day_by_day(time, value)
+ with (timescaledb.continuous) as
+ SELECT time_bucket('1 day', created, 'Europe/Berlin') AS "time",
+ round((last(value, created) - first(value, created)) * 100.) / 100. AS value
+ FROM metrics
+ WHERE type_id = 5
+ GROUP BY 1;
+ ```
+
+ 1. Add a refresh policy to keep `kwh_day_by_day` up-to-date:
+
+ ```sql
+ SELECT add_continuous_aggregate_policy('kwh_day_by_day',
+ start_offset => NULL,
+ end_offset => INTERVAL '1 hour',
+ schedule_interval => INTERVAL '1 hour');
+ ```
+
+1. **Monitor energy consumption on an hourly basis**
+
+ 1. Create a continuous aggregate `kwh_hour_by_hour` for energy consumption:
+
+ ```sql
+ CREATE MATERIALIZED VIEW kwh_hour_by_hour(time, value)
+ with (timescaledb.continuous) as
+ SELECT time_bucket('01:00:00', metrics.created, 'Europe/Berlin') AS "time",
+ round((last(value, created) - first(value, created)) * 100.) / 100. AS value
+ FROM metrics
+ WHERE type_id = 5
+ GROUP BY 1;
+ ```
+
+ 1. Add a refresh policy to keep the continuous aggregate up-to-date:
+
+ ```sql
+ SELECT add_continuous_aggregate_policy('kwh_hour_by_hour',
+ start_offset => NULL,
+ end_offset => INTERVAL '1 hour',
+ schedule_interval => INTERVAL '1 hour');
+ ```
+
+1. **Analyze your data**
+
+ Now you have made continuous aggregates, it could be a good idea to use them to perform analytics on your data.
+ For example, to see how average energy consumption changes during weekdays over the last year, run the following query:
+ ```sql
+ WITH per_day AS (
+ SELECT
+ time,
+ value
+ FROM kwh_day_by_day
+ WHERE "time" at time zone 'Europe/Berlin' > date_trunc('month', time) - interval '1 year'
+ ORDER BY 1
+ ), daily AS (
+ SELECT
+ to_char(time, 'Dy') as day,
+ value
+ FROM per_day
+ ), percentile AS (
+ SELECT
+ day,
+ approx_percentile(0.50, percentile_agg(value)) as value
+ FROM daily
+ GROUP BY 1
+ ORDER BY 1
+ )
+ SELECT
+ d.day,
+ d.ordinal,
+ pd.value
+ FROM unnest(array['Sun', 'Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat']) WITH ORDINALITY AS d(day, ordinal)
+ LEFT JOIN percentile pd ON lower(pd.day) = lower(d.day);
+ ```
+
+ You see something like:
+
+ | day | ordinal | value |
+ | --- | ------- | ----- |
+ | Mon | 2 | 23.08078714975423 |
+ | Sun | 1 | 19.511430831944395 |
+ | Tue | 3 | 25.003118897837307 |
+ | Wed | 4 | 8.09300571759772 |
diff --git a/_partials/_use-case-setup-blockchain-dataset.md b/_partials/_use-case-setup-blockchain-dataset.md
new file mode 100644
index 0000000000..c1ddd2669f
--- /dev/null
+++ b/_partials/_use-case-setup-blockchain-dataset.md
@@ -0,0 +1,18 @@
+
+
+import CreateHypertableBlockchain from "versionContent/_partials/_create-hypertable-blockchain.mdx";
+import AddDataBlockchain from "versionContent/_partials/_add-data-blockchain.mdx";
+import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
+
+# Ingest data into a $SERVICE_LONG
+
+This tutorial uses a dataset that contains Bitcoin blockchain data for
+the past five days, in a hypertable named `transactions`.
+
+## Prerequisites
+
+
+
+
+
+
diff --git a/_partials/_use-case-transport-geolocation.md b/_partials/_use-case-transport-geolocation.md
new file mode 100644
index 0000000000..8156143720
--- /dev/null
+++ b/_partials/_use-case-transport-geolocation.md
@@ -0,0 +1,88 @@
+
+### Setup your data for geospatial queries
+
+To add geospatial analysis to your ride count visualization, you need geospatial data to work out which trips
+originated where. As $TIMESCALE_DB is compatible with all PostgreSQL extensions, use [PostGIS][postgis] to slice
+data by time and location.
+
+
+
+1. Connect to your [$SERVICE_LONG][in-console-editors] and add the PostGIS extension:
+
+ ```sql
+ CREATE EXTENSION postgis;
+ ```
+
+1. Add geometry columns for pick up and drop off locations:
+
+ ```sql
+ ALTER TABLE rides ADD COLUMN pickup_geom geometry(POINT,2163);
+ ALTER TABLE rides ADD COLUMN dropoff_geom geometry(POINT,2163);
+ ```
+
+1. Convert the latitude and longitude points into geometry coordinates that work with PostGIS.
+
+ ```sql
+ UPDATE rides SET pickup_geom = ST_Transform(ST_SetSRID(ST_MakePoint(pickup_longitude,pickup_latitude),4326),2163),
+ dropoff_geom = ST_Transform(ST_SetSRID(ST_MakePoint(dropoff_longitude,dropoff_latitude),4326),2163);
+ ```
+ This updates 10,906,860 rows of data on both columns, it takes a while. Coffee is your friend.
+
+
+
+### Visualize the area where you can make the most money
+
+In this section you visualize a query that returns rides longer than 5 miles for
+trips taken within 2 km of Times Square. The data includes the distance travelled and
+is `GROUP BY` `trip_distance` and location so that Grafana can plot the data properly.
+
+This enables you to see where a taxi driver is most likely to pick up a passenger who wants a longer ride,
+and make more money.
+
+
+
+1. **Create a geolocalization dashboard**
+
+ 1. In Grafana, create a new dashboard that is connected to your $SERVICE_LONG data source with a Geomap
+ visualization.
+
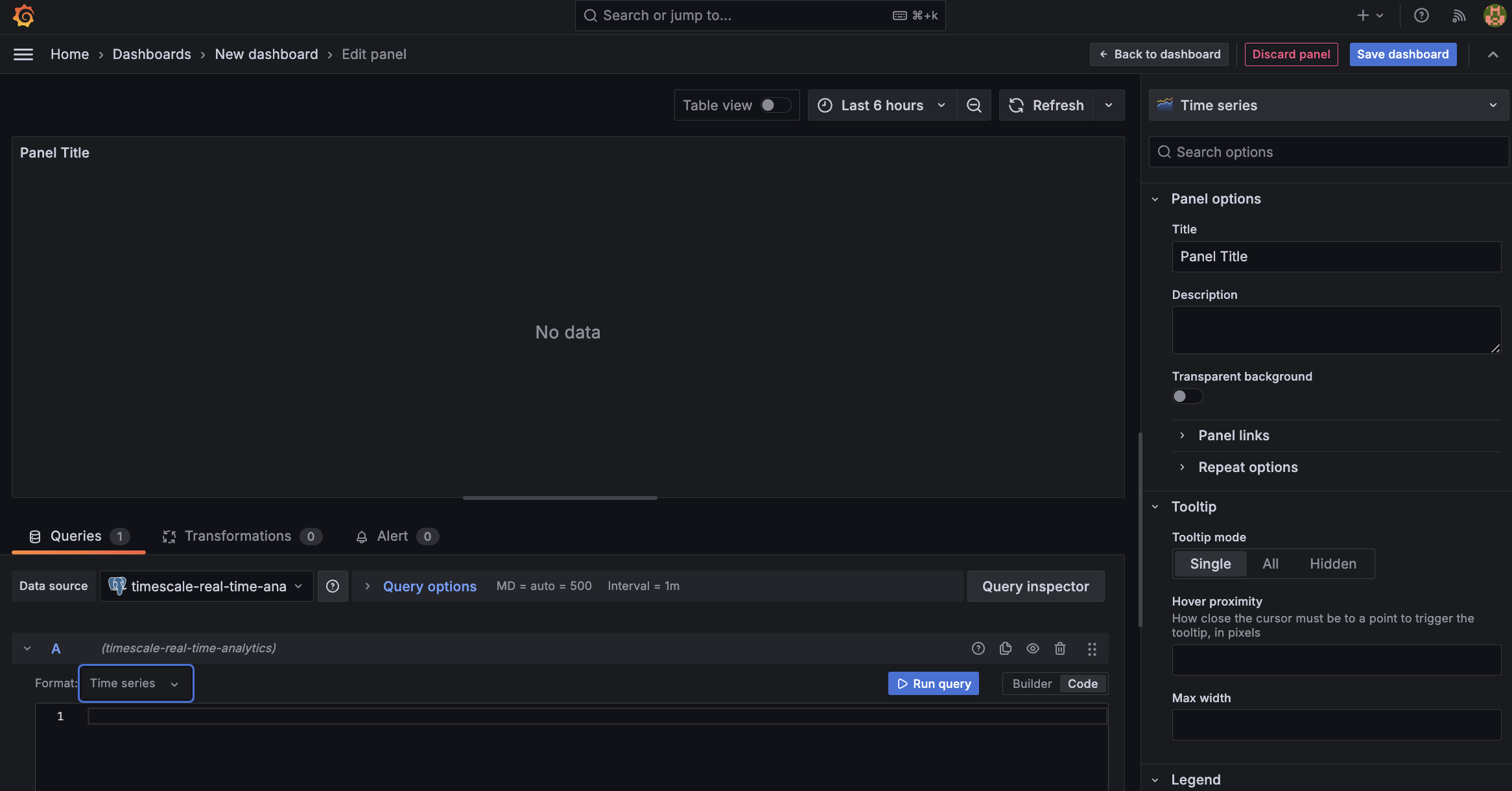
+ 1. In the `Queries` section, select `Code`, then select the Time series `Format`.
+
+ 
+
+ 1. To find rides longer than 5 miles in Manhattan, paste the following query:
+
+ ```sql
+ SELECT time_bucket('5m', rides.pickup_datetime) AS time,
+ rides.trip_distance AS value,
+ rides.pickup_latitude AS latitude,
+ rides.pickup_longitude AS longitude
+ FROM rides
+ WHERE rides.pickup_datetime BETWEEN '2016-01-01T01:41:55.986Z' AND '2016-01-01T07:41:55.986Z' AND
+ ST_Distance(pickup_geom,
+ ST_Transform(ST_SetSRID(ST_MakePoint(-73.9851,40.7589),4326),2163)
+ ) < 2000
+ GROUP BY time,
+ rides.trip_distance,
+ rides.pickup_latitude,
+ rides.pickup_longitude
+ ORDER BY time
+ LIMIT 500;
+ ```
+ You see a world map with a dot on New York.
+ 1. Zoom into your map to see the visualization clearly.
+
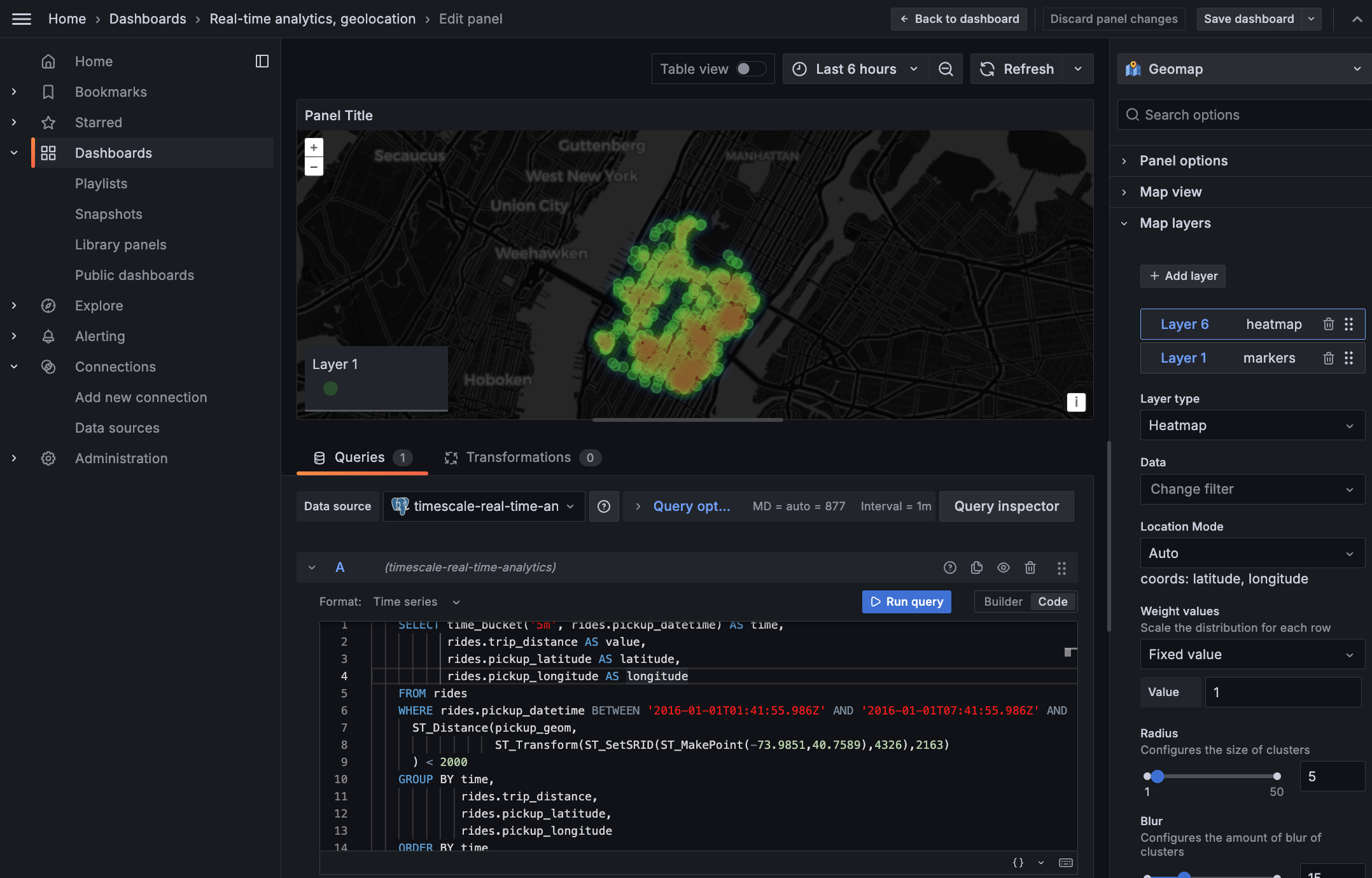
+1. **Customize the visualization**
+
+ 1. In the Geomap options, under `Map Layers`, click `+ Add layer` and select `Heatmap`.
+ You now see the areas where a taxi driver is most likely to pick up a passenger who wants a
+ longer ride, and make more money.
+
+ 
+
+
+
+
+
+[in-console-editors]: /getting-started/:currentVersion:/run-queries-from-console/
+[postgis]: http://postgis.net/
diff --git a/_partials/_where-to-next.md b/_partials/_where-to-next.md
index 5d1124a297..62a9c7ff4c 100644
--- a/_partials/_where-to-next.md
+++ b/_partials/_where-to-next.md
@@ -1,7 +1,11 @@
-Now you have TimescaleDB running, have a look at the:
+What next? [Try the main features offered by Timescale][try-timescale-features], see the [use case tutorials][tutorials],
+interact with the data in your $SERVICE_LONG using [your favorite programming language][connect-with-code], integrate
+your $SERVICE_LONG with a range of [third-party tools][integrations], plain old [Use Timescale][use-timescale], or dive
+into [the API][use-the-api].
-* [Tutorials][tutorials]: walk through a variety of business scenarios using example datasets.
-* [Use Timescale][tsdb-docs]: browse the features available with TimescaleDB.
-
-[tsdb-docs]: /use-timescale/:currentVersion:/
[tutorials]: /tutorials/:currentVersion:/
+[connect-with-code]: /quick-start/:currentVersion:/
+[integrations]: /use-timescale/:currentVersion:/integrations/
+[use-the-api]: /api/:currentVersion:/
+[use-timescale]: /use-timescale/:currentVersion:/
+[try-timescale-features]: /getting-started/:currentVersion:/try-key-features-timescale-products/
diff --git a/api/compression/add_compression_policy.md b/api/compression/add_compression_policy.md
index 440585e6de..7a154443c3 100644
--- a/api/compression/add_compression_policy.md
+++ b/api/compression/add_compression_policy.md
@@ -11,10 +11,6 @@ api:
import Deprecated2180 from "versionContent/_partials/_deprecated_2_18_0.mdx";
-import Deprecated2180 from "versionContent/_partials/_deprecated_2_18_0.mdx";
-
-import Deprecated2180 from "versionContent/_partials/_deprecated_2_18_0.mdx";
-
# add_compression_policy()
Replaced by add_columnstore_policy().
diff --git a/api/compression/chunk_compression_stats.md b/api/compression/chunk_compression_stats.md
index 25e9e80229..6b7014bf3b 100644
--- a/api/compression/chunk_compression_stats.md
+++ b/api/compression/chunk_compression_stats.md
@@ -11,10 +11,6 @@ api:
import Deprecated2180 from "versionContent/_partials/_deprecated_2_18_0.mdx";
-import Deprecated2180 from "versionContent/_partials/_deprecated_2_18_0.mdx";
-
-import Deprecated2180 from "versionContent/_partials/_deprecated_2_18_0.mdx";
-
# chunk_compression_stats() Community
Replaced by chunk_columnstore_stats().
diff --git a/api/compression/decompress_chunk.md b/api/compression/decompress_chunk.md
index cfa3aa8080..4cca76dd76 100644
--- a/api/compression/decompress_chunk.md
+++ b/api/compression/decompress_chunk.md
@@ -10,10 +10,6 @@ api:
import Deprecated2180 from "versionContent/_partials/_deprecated_2_18_0.mdx";
-import Deprecated2180 from "versionContent/_partials/_deprecated_2_18_0.mdx";
-
-import Deprecated2180 from "versionContent/_partials/_deprecated_2_18_0.mdx";
-
# decompress_chunk() Community
Replaced by convert_to_rowstore().
diff --git a/api/compression/hypertable_compression_stats.md b/api/compression/hypertable_compression_stats.md
index 93acde5677..39f141ff76 100644
--- a/api/compression/hypertable_compression_stats.md
+++ b/api/compression/hypertable_compression_stats.md
@@ -11,10 +11,6 @@ api:
import Deprecated2180 from "versionContent/_partials/_deprecated_2_18_0.mdx";
-import Deprecated2180 from "versionContent/_partials/_deprecated_2_18_0.mdx";
-
-import Deprecated2180 from "versionContent/_partials/_deprecated_2_18_0.mdx";
-
# hypertable_compression_stats() Community
Replaced by hypertable_columnstore_stats().
diff --git a/getting-started/index.md b/getting-started/index.md
index a607cbebdc..07d039ec6e 100644
--- a/getting-started/index.md
+++ b/getting-started/index.md
@@ -16,21 +16,24 @@ import WhereNext from "versionContent/_partials/_where-to-next.mdx";
This section shows you how to:
-1. [Create and connect to a Timescale service][services-create]
-1. [Run queries from Timescale Console][run-queries-from-console]
-1. [Ingest some real financial data into your database][ingest-data]
-1. [Construct some interesting queries][queries] Try out some live queries
-1. [Create and query a continuous aggregate][caggs]
+1. [Create and connect to a $SERVICE_LONG][services-create]: choose the capabilities that match your business and
+ engineering needs on $COMPANY's cloud-based PostgreSQL platform.
+1. [Run queries from $CONSOLE][run-queries-from-console]: securely interact your data in the $CONSOLE UI.
+1. [Try the main features in Timescale products][test-drive]: rapidly implement the features in $CLOUD_LONG that
+ enable you to ingest and query data faster while keeping prices low.
-Already know the basics? See the
-[more advanced tutorials][tutorials], or see how to
-[Use Timescale][use-timescale].
+What next? See the [use case tutorials][tutorials], interact with the data in your $SERVICE_LONG using
+[your favorite programming language][connect-with-code], integrate your $SERVICE_LONG with a range of
+[third-party tools][integrations], plain old [Use Timescale][use-timescale], or dive into [the API][use-the-api].
[tutorials]: /tutorials/:currentVersion:/
+[connect-with-code]: /quick-start/:currentVersion:/
+[integrations]: /use-timescale/:currentVersion:/integrations/
+[use-the-api]: /api/:currentVersion:/
[use-timescale]: /use-timescale/:currentVersion:/
[services-create]: /getting-started/:currentVersion:/services#create-your-timescale-account
[services-connect]: /getting-started/:currentVersion:/services/#connect-to-your-service
+[test-drive]: /getting-started/:currentVersion:/try-key-features-timescale-products/
[run-queries-from-console]: /getting-started/:currentVersion:/run-queries-from-console/
-[ingest-data]: /getting-started/:currentVersion:/time-series-data/
-[queries]: /getting-started/:currentVersion:/queries/
-[caggs]: /getting-started/:currentVersion:/aggregation/
+[ingest-data]: /getting-started/:currentVersion:/try-key-features-timescale-products/#optimize-time-series-data-in-hypertables
+
diff --git a/getting-started/page-index/page-index.js b/getting-started/page-index/page-index.js
index ef51f973f8..6ec2fac83e 100644
--- a/getting-started/page-index/page-index.js
+++ b/getting-started/page-index/page-index.js
@@ -15,29 +15,9 @@ module.exports = [
excerpt: "Run your queries securely from inside Timescale Console",
},
{
- title: "Tables and hypertables",
- href: "tables-hypertables",
- excerpt: "Create tables and hypertables for your data",
- },
- {
- title: "Time-series data",
- href: "time-series-data",
- excerpt: "Add time-series data to your database",
- },
- {
- title: "Queries",
- href: "queries",
- excerpt: "Query your data using full SQL",
- },
- {
- title: "Aggregation",
- href: "aggregation",
- excerpt: "Query aggregated data, and create a continuous aggregate",
- },
- {
- title: "Next steps",
- href: "next-steps",
- excerpt: "Get even more from your Timescale database",
+ title: "Try out key features of Timescale products",
+ href: "try-key-features-timescale-products",
+ excerpt: "Improve database performance with Hypertables, time bucketing, continuous aggregates, compression, data tiering, and high availability",
},
],
},
diff --git a/getting-started/run-queries-from-console.md b/getting-started/run-queries-from-console.md
index 51ea1b6b80..955fab154b 100644
--- a/getting-started/run-queries-from-console.md
+++ b/getting-started/run-queries-from-console.md
@@ -6,6 +6,8 @@ layout_components: [next_prev_large]
content_group: Getting started
---
+import WhereNext from "versionContent/_partials/_where-to-next.mdx";
+
# Run your queries from Timescale Console
As Timescale Cloud is based on PostgreSQL, you can use lots of [different tools][integrations] to
@@ -226,6 +228,7 @@ To use SQL editor with Timescale:
details.
+
[readreplica]: /use-timescale/:currentVersion:/ha-replicas/read-scaling/
[run-popsql]: /getting-started/:currentVersion:/run-queries-from-console/#data-mode
diff --git a/getting-started/services.md b/getting-started/services.md
index 1dfb3efa87..9ca39ab1a1 100644
--- a/getting-started/services.md
+++ b/getting-started/services.md
@@ -11,6 +11,7 @@ import Connect from "versionContent/_partials/_cloud-connect.mdx";
import CreateAHypertable from "versionContent/_partials/_create-hypertable.mdx";
import ServiceOverview from "versionContent/_partials/_service-overview.mdx";
import CloudIntro from "versionContent/_partials/_cloud-intro.mdx";
+import WhereNext from "versionContent/_partials/_where-to-next.mdx";
# Create your first $SERVICE_LONG
@@ -59,11 +60,10 @@ A $SERVICE_LONG comes with access control to its data. To be able to run queries
-## Create a hypertable
+And that is it, you are up and running. Enjoy developing with $COMPANY.
-
+
-And that is it, you are up and running. Enjoy developing with $CLOUD_LONG.
[tsc-portal]: https://console.cloud.timescale.com/
[services-how-to]: /use-timescale/:currentVersion:/services/
diff --git a/getting-started/tables-hypertables.md b/getting-started/tables-hypertables.md
index 43589aaf13..f336016e83 100644
--- a/getting-started/tables-hypertables.md
+++ b/getting-started/tables-hypertables.md
@@ -1,6 +1,6 @@
---
title: Tables and hypertables
-excerpt: Hypertables are PostgreSQL tables designed to boost the performance of your real-time analytical queries. Create a table and then convert it into a hypertable in Timescale Console
+excerpt: Create tables and hypertables in your Timescale account
products: [cloud]
keywords: [hypertables, create]
layout_components: [next_prev_large]
@@ -13,17 +13,6 @@ import HypertableIntro from "versionContent/_partials/_hypertables-intro.mdx";
-Databases are made up of tables that contain your data. In PostgreSQL, these
-tables are relational, so the data in one table relates to the data in another
-table. In Timescale, you use regular PostgreSQL relational tables, in addition
-to special time-series hypertables.
-
-Hypertables are designed specifically for time-series data, so they have a few
-special qualities that makes them different to a regular PostgreSQL table. A
-hypertable is always partitioned on time, but can also be partitioned on
-additional columns as well. The other special thing about hypertables is that
-they are broken down into smaller tables called chunks.
-
In this section, you create a hypertable for time-series data, and regular
PostgreSQL tables for relational data. You also create an index on your
hypertable, which isn't required, but can help your queries run more efficiently.
diff --git a/getting-started/try-key-features-timescale-products.md b/getting-started/try-key-features-timescale-products.md
new file mode 100644
index 0000000000..842cf1afb6
--- /dev/null
+++ b/getting-started/try-key-features-timescale-products.md
@@ -0,0 +1,392 @@
+---
+title: Try out key features of Timescale products
+excerpt: Improve database performance with hypertables, time bucketing, compression and continuous aggregates.
+products: [cloud]
+content_group: Getting started
+---
+
+import HASetup from 'versionContent/_partials/_high-availability-setup.mdx';
+import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
+
+# Try out key features of Timescale products
+
+$CLOUD_LONG scales PostgreSQL to ingest and query vast amounts of live data. $CLOUD_LONG
+provides a range of features and optimizations that supercharge your queries while keeping the
+costs down. For example:
+* The hypercore row-columnar engine makes queries up to 350x faster, ingests 44% faster, and reduces storage by 90%.
+* Tiered storage seamlessly moves your data from high performance storage for frequently access data to low cost bottomless storage for rarely accessed data.
+
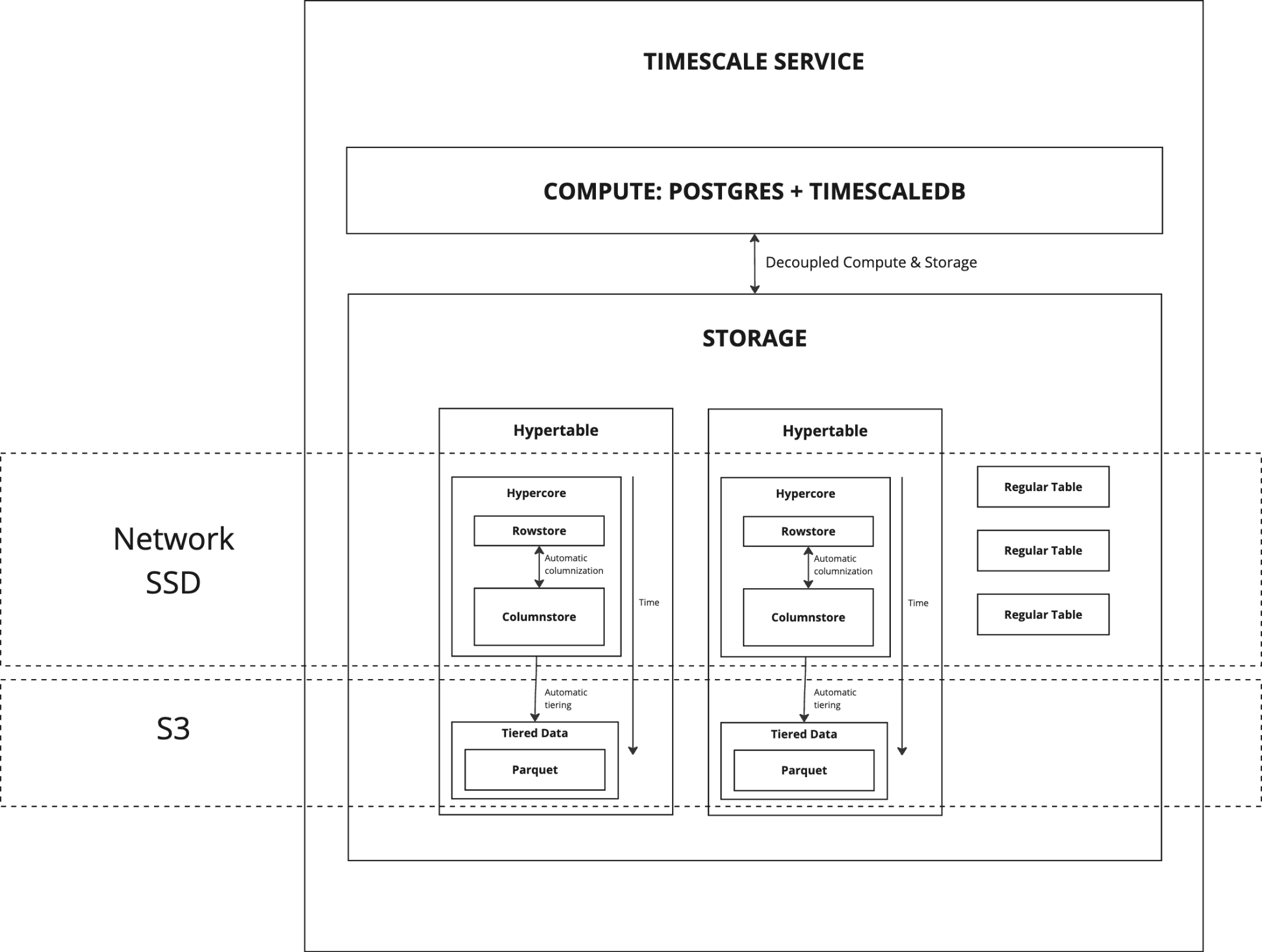
+The following figure shows the main features and tiered data in $CLOUD_LONG:
+
+
+
+This page gives shows you how to rapidly implement the features in $CLOUD_LONG that enable you to
+ingest and query data faster while keeping prices low.
+
+## Prerequisites
+
+
+
+## Optimize time-series data in hypertables
+
+Time-series data represents how a system, process, or behavior changes over time. Hypertables are PostgreSQL tables
+that help you improve insert and query performance by automatically partition your data by time. Each hypertable
+is made up of child tables called chunks. Each chunk is assigned a range of time, and only
+contains data from that range. You can also tune hypertables to increase performance
+even more.
+
+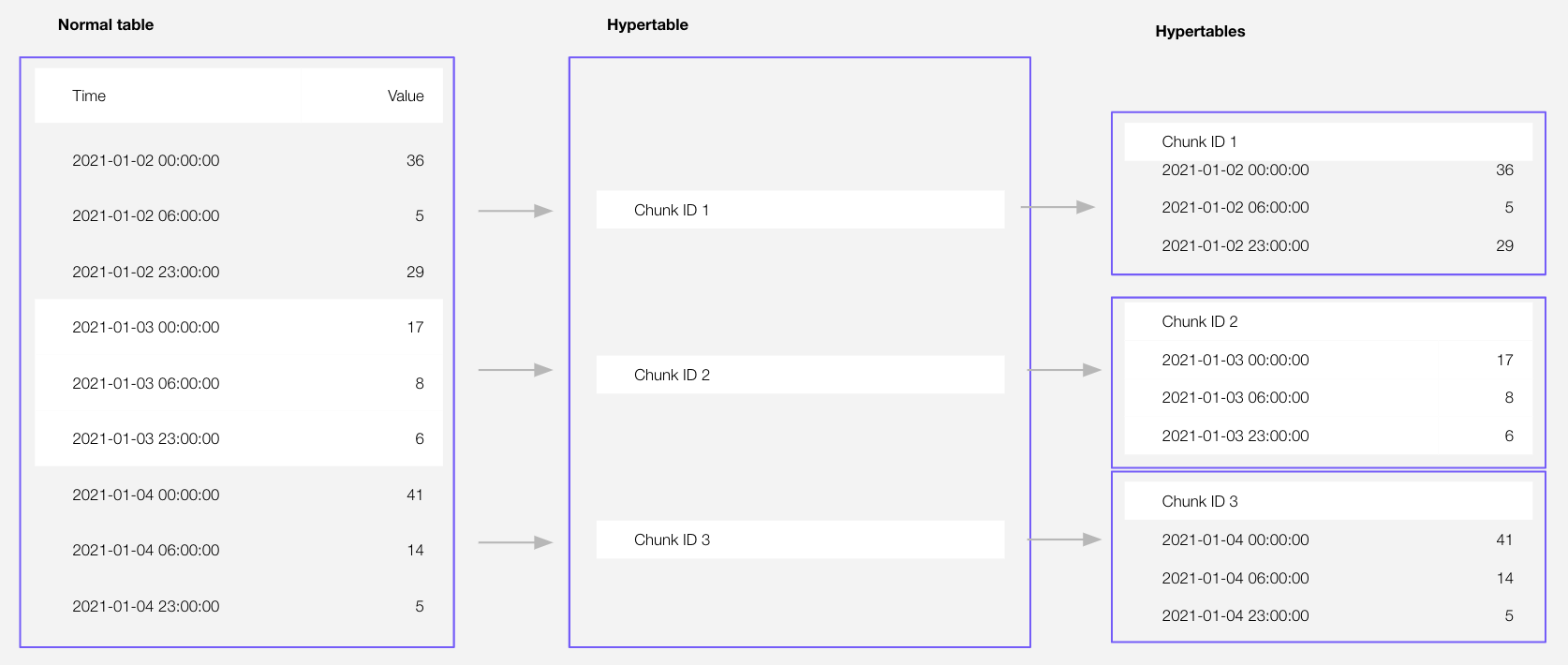
+
+Hypertables exist alongside regular PostgreSQL tables.
+You use regular PostgreSQL tables for relational data, and interact with hypertables
+and regular PostgreSQL tables in the same way.
+
+This section shows you how to create regular tables and hypertables, and import
+relational and time-series data from external files.
+
+
+
+1. **Import some time-series data into your hypertable**
+
+ 1. Unzip [real_time_stock_data.zip](https://assets.timescale.com/docs/downloads/get-started/real_time_stock_data.zip) to a ``.
+
+ This test dataset contains second-by-second stock-trade data for the top 100 most-traded symbols
+ and a regular table of company symbols and company names.
+
+ To import up to 100GB of data directly from your current PostgreSQL based database,
+ [migrate with downtime][migrate-with-downtime] using native PostgreSQL tooling. To seamlessly import 100GB-10TB+
+ of data, use the [live migration][migrate-live] tooling supplied by $COMPANY. To add data from non-PostgreSQL
+ data sources, see [Import and ingest data][data-ingest].
+
+ 1. Upload data from the CSVs to your $SERVICE_SHORT:
+
+
+
+
+
+ The $CONSOLE data upload creates the tables for you from the data you are uploading:
+ 1. In [$CONSOLE][portal-ops-mode], select the service to add data to, then click **Actions** > **Upload CSV**.
+ 1. Drag `/tutorial_sample_tick.csv` to `Upload .CSV` and change `New table name`, to `stocks_real_time`.
+ 1. Enable `hypertable partition` for the `time` column and click `Upload CSV`.
+ The upload wizard creates a hypertable containing the data from the CSV file.
+ 1. When the data is uploaded, close `Upload .CSV`.
+ If you want to have a quick look at your data, press `Run` .
+ 1. Repeat the process with `/tutorial_sample_company.csv` and rename to `company`.
+ There is no time-series data in this table, so you don't see the `hypertable partition` option.
+
+
+
+
+
+ 1. In Terminal, navigate to `` and connect to your $SERVICE_SHORT.
+ ```bash
+ psql -d "postgres://:@:/"
+ ```
+ The connection information for a $SERVICE_SHORT is available in the file you downloaded when you created it.
+
+ 2. Create tables for the data to import
+
+ - For the time-series data:
+ 1. In your sql client, create a normal PostgreSQL table:
+
+ ```sql
+ CREATE TABLE stocks_real_time (
+ time TIMESTAMPTZ NOT NULL,
+ symbol TEXT NOT NULL,
+ price DOUBLE PRECISION NULL,
+ day_volume INT NULL
+ );
+ ```
+ 1. Convert `stocks_real_time` to a hypertable:
+ ```sql
+ SELECT create_hypertable('stocks_real_time', by_range('time'));
+ ```
+ To more fully understand how hypertables work, and how to optimize them for performance by
+ tuning chunk intervals and enabling chunk skipping, see [the hypertables documentation][hypertables-section].
+
+ - For the relational data:
+
+ In your sql client, create a normal PostgreSQL table:
+ ```sql
+ CREATE TABLE company (
+ symbol TEXT NOT NULL,
+ name TEXT NOT NULL
+ );
+ ```
+
+ 3. Upload the dataset to your $SERVICE_SHORT
+ ```sql
+ \COPY stocks_real_time from './tutorial_sample_tick.csv' DELIMITER ',' CSV HEADER;
+ \COPY company from './tutorial_sample_company.csv' DELIMITER ',' CSV HEADER;
+ ```
+
+
+
+
+
+ To more fully understand how hypertables work, and how to optimize them for performance by
+ tuning chunk intervals and enabling chunk skipping, see [the hypertables documentation][hypertables-section].
+
+1. **Have a quick look at your data**
+
+ You query hypertables in exactly the same way as you would a relational PostgreSQL table.
+ Use one of the following SQL editors to run a query and see the data you uploaded:
+ - **Data mode**: write queries, visualize data, and share your results in [$CONSOLE][portal-data-mode] for all your $SERVICE_LONGs.
+ - **SQL editor**: write, fix, and organize SQL faster and more accurately in [$CONSOLE][portal-ops-mode] for a $SERVICE_LONG.
+ - **psql**: easily run queries on your $SERVICE_LONGs or self-hosted TimescaleDB deployment from Terminal.
+
+
+
+
+
+## Write fast analytical queries on frequently access data using time buckets and continuous aggregates
+
+Aggregation is a way of combing data to get insights from it. Average, sum, and count are all
+example of simple aggregates. However, with large amounts of data aggregation slows things down, quickly.
+Continuous aggregates are a kind of hypertable that is refreshed automatically in
+the background as new data is added, or old data is modified. Changes to your dataset are tracked,
+and the hypertable behind the continuous aggregate is automatically updated in the background.
+
+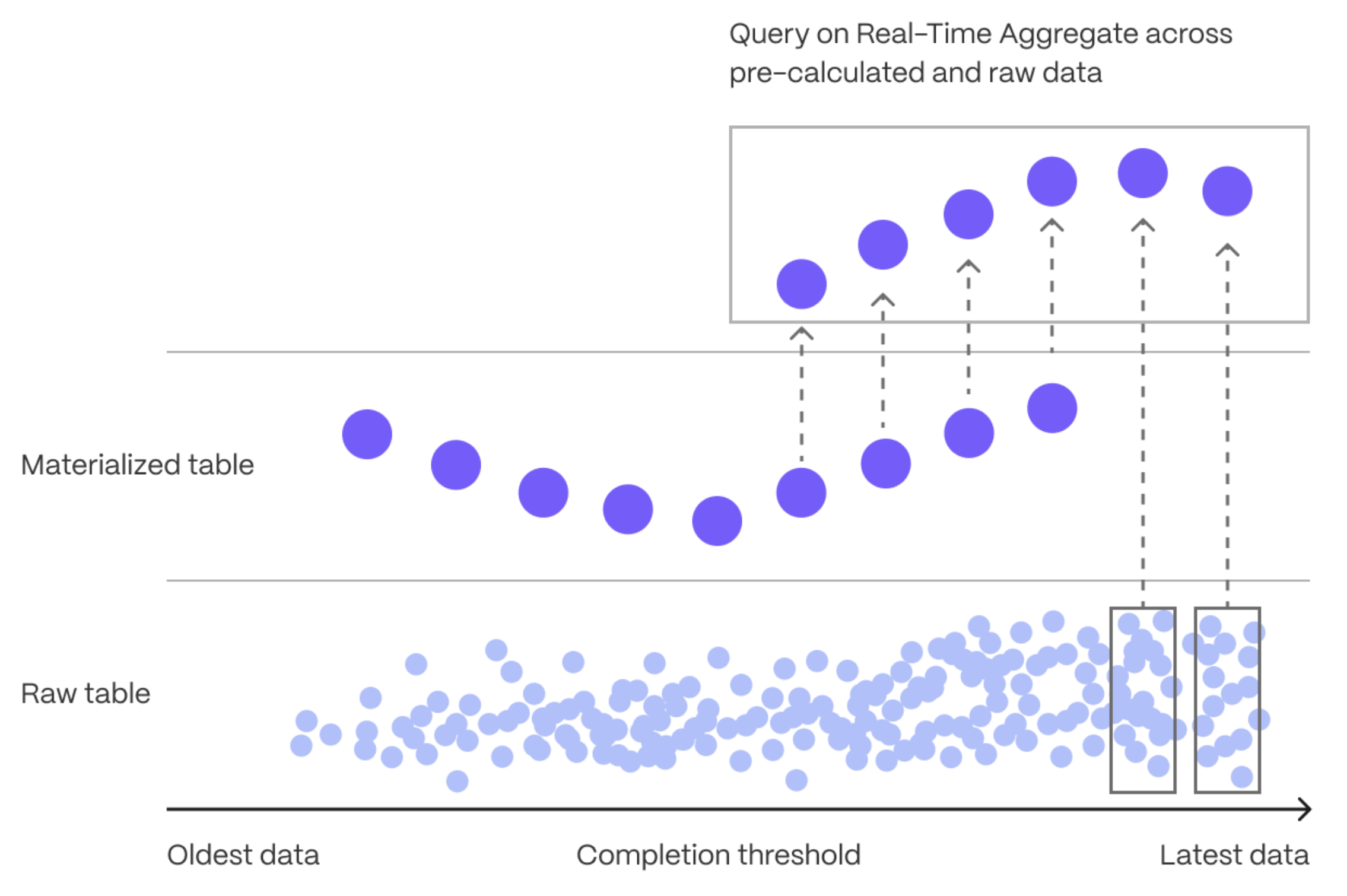
+
+You create continuous aggregates on uncompressed data in high-performance storage. They continue to work
+on [data in the columnstore][test-drive-enable-compression]
+and [rarely accessed data in tiered storage][test-drive-tiered-storage]. You can even
+create [continuous aggregates on top of your continuous aggregates][hierarchical-caggs].
+
+You use time buckets to create a continuous aggregate. Time buckets aggregate data in hypertables by time
+interval. For example, a 5-minute, 1-hour, or 3-day bucket. The data grouped in a time bucket use a single
+timestamp. Continuous aggregates minimize the number of records that you need to look up to perform your
+query.
+
+This section show you how to run fast analytical queries using time buckets and continuous aggregates in
+$CONSOLE. You can also do this using psql.
+
+
+
+
+
+
+
+1. **In [$CONSOLE][portal-ops-mode], select the service you uploaded data to, then click `SQL Editor`**.
+
+1. **Create a continuous aggregate**
+
+ For a continuous aggregate, data grouped using a time bucket is stored in a
+ PostgreSQL `MATERIALIZED VIEW` in a hypertable. `timescaledb.continuous` ensures that this data
+ is always up to date.
+ In your SQL editor, use the following code to create a continuous aggregate on the real time data in
+ the `stocks_real_time` table:
+
+ ```sql
+ CREATE MATERIALIZED VIEW stock_candlestick_daily
+ WITH (timescaledb.continuous) AS
+ SELECT
+ time_bucket('1 day', "time") AS day,
+ symbol,
+ max(price) AS high,
+ first(price, time) AS open,
+ last(price, time) AS close,
+ min(price) AS low
+ FROM stocks_real_time srt
+ GROUP BY day, symbol;
+ ```
+
+ This continuous aggregate creates the [candlestick chart][charts] data you use to visualize
+ the price change of an asset.
+
+1. **Create a policy to refresh the view every hour**
+
+ ```sql
+ SELECT add_continuous_aggregate_policy('stock_candlestick_daily',
+ start_offset => INTERVAL '3 weeks',
+ end_offset => INTERVAL '24 hours',
+ schedule_interval => INTERVAL '3 hours');
+ ```
+
+1. **Have a quick look at your data**
+
+ You query continuous aggregates exactly the same way as your other tables. To query the `stock_candlestick_daily`
+ continuous aggregate for all stocks:
+
+
+
+
+
+
+
+
+
+
+
+
+1. **In [$CONSOLE][portal-ops-mode], select the service you uploaded data to**.
+1. **Click `Operations` > `Continuous aggregates`, select `stocks_real_time`, then click `Create continuous aggregate`**.
+ 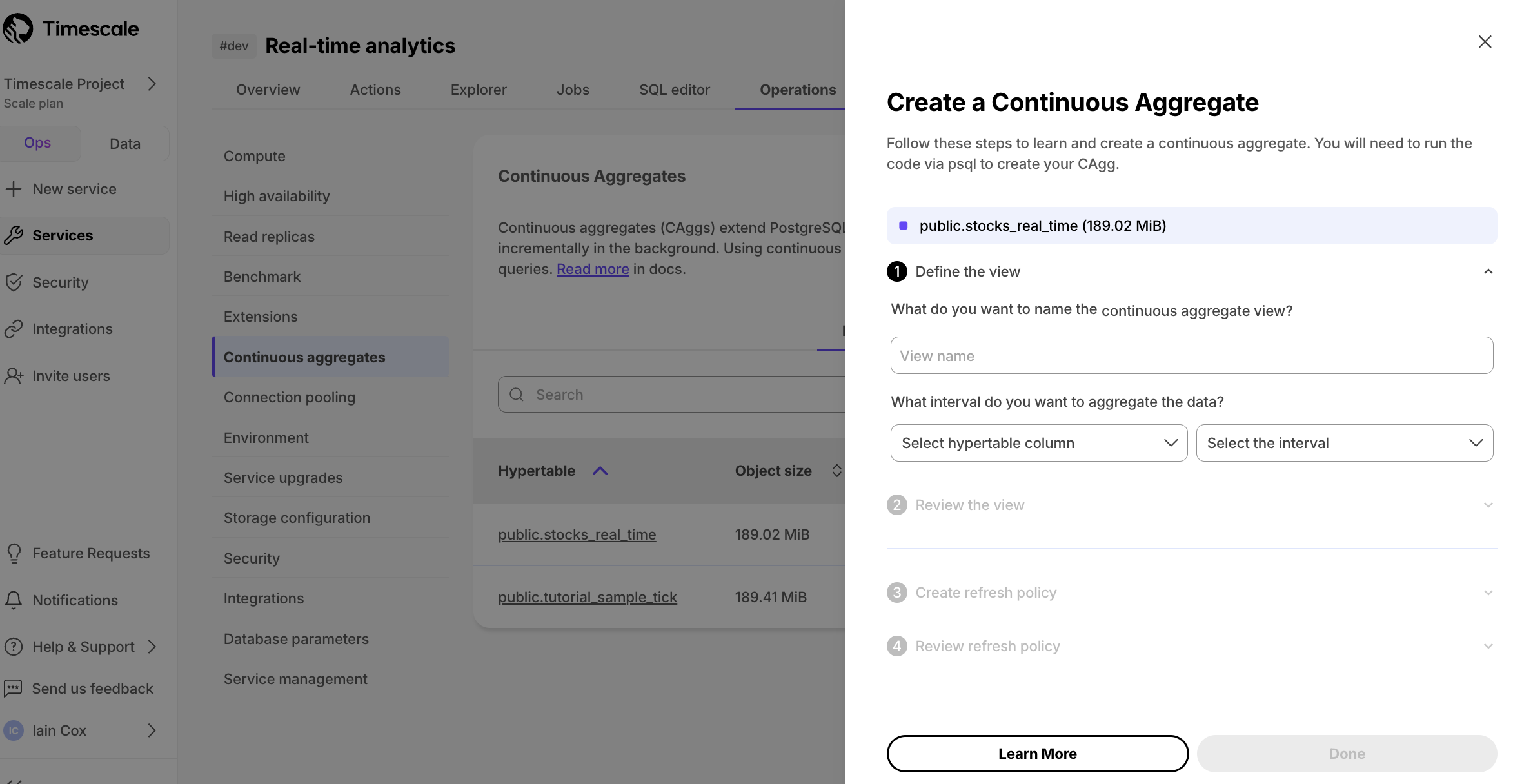
+1. **Create a view called `stock_candlestick_daily` on the `time` column with an interval of `1 day`, then click `Next step`**.
+1. **Update the view SQL with the following functions, then click `Run`**
+ ```sql
+ CREATE MATERIALIZED VIEW stock_candlestick_daily
+ WITH (timescaledb.continuous) AS
+ SELECT
+ time_bucket('1 day', "time") AS bucket,
+ symbol,
+ max(price) AS high,
+ first(price, time) AS open,
+ last(price, time) AS close,
+ min(price) AS low
+ FROM "public"."stocks_real_time" srt
+ GROUP BY bucket, symbol;
+ ```
+1. **When the view is created, click `Next step`**
+1. **Define a refresh policy with the following values, then click `Next step`**
+ - `Set the start offset`: `3 weeks`
+ - `Set the end offset`: `24 hours`
+ - `Set the schedule interval`: `3 hours`
+1. **Click `Create continuous aggregate`, then click `Run`**
+
+$CLOUD_LONG creates the continuous aggregate and displays the aggregate ID in $CONSOLE. Click `DONE` to close the wizard.
+
+
+
+
+
+
+
+To see the change in terms of query time and data returned between a regular query and
+a continuous aggregate, run the query part of the continuous aggregate
+( `SELECT ...GROUP BY day, symbol;` ) and compare the results.
+
+## Prepare your data for real-time analytics with hypercore
+
+Hypercore is the Timescale hybrid row-columnar storage engine, designed specifically for real-time analytics and
+powered by time-series data. The advantage of Hypercore is its ability to seamlessly switch between row-oriented and
+column-oriented storage. This flexibility enables Timescale Cloud to deliver the best of both worlds, solving the key
+challenges in real-time analytics.
+
+When you convert chunks from the rowstore to the columnstore, multiple records are grouped into a single row.
+The columns of this row hold an array-like structure that stores all the data. Because a single row takes up less disk
+space, you can reduce your chunk size by more than 90%, and can also speed up your queries. This saves on storage costs,
+and keeps your queries operating at lightning speed.
+
+Best practice is to compress data that is no longer needed for highest performance queries, but is still accessed regularly. For example, last week's stock
+market data.
+
+
+
+1. **Enable hypercore on a hypertable**
+
+ Create a [job][job] that automatically moves chunks in a hypertable to the columnstore at a specific time interval.
+
+ ```sql
+ ALTER TABLE stocks_real_time SET (
+ timescaledb.enable_columnstore = true,
+ timescaledb.segmentby = 'symbol');
+ ```
+
+1. **Add a policy to convert chunks to the columnstore at a specific time interval**
+
+ For example, 60 days after the data was added to the table:
+ ``` sql
+ CALL add_columnstore_policy('stocks_real_time', after => INTERVAL '60d');
+ ```
+ See [add_columnstore_policy][add_columnstore_policy].
+
+
+
+
+## Reduce storage charges for rarely accessed data using tiered storage
+
+In the previous sections, you used continuous aggregates to make fast analytical queries, and
+compression to reduce storage costs on frequently accessed data. To reduce storage costs even more,
+you create tiering policies to move rarely accessed data to the object store. The object store is
+low-cost bottomless data storage built on Amazon S3. However, no matter the tier, you can
+[query your data when you need][querying-tiered-data]. $CLOUD_LONG seamlessly accesses the correct storage
+tier and generates the response.
+
+Data tiering is available in the [scale and enterprise][pricing-plans] pricing plans for $CLOUD_LONG.
+
+To setup data tiering:
+
+
+
+1. **Enable data tiering**
+
+ 1. In [$CONSOLE][portal-ops-mode], select the service to modify.
+
+ You see the `Overview` section.
+
+ 1. Scroll down, then click `Enable tiered storage`.
+
+ 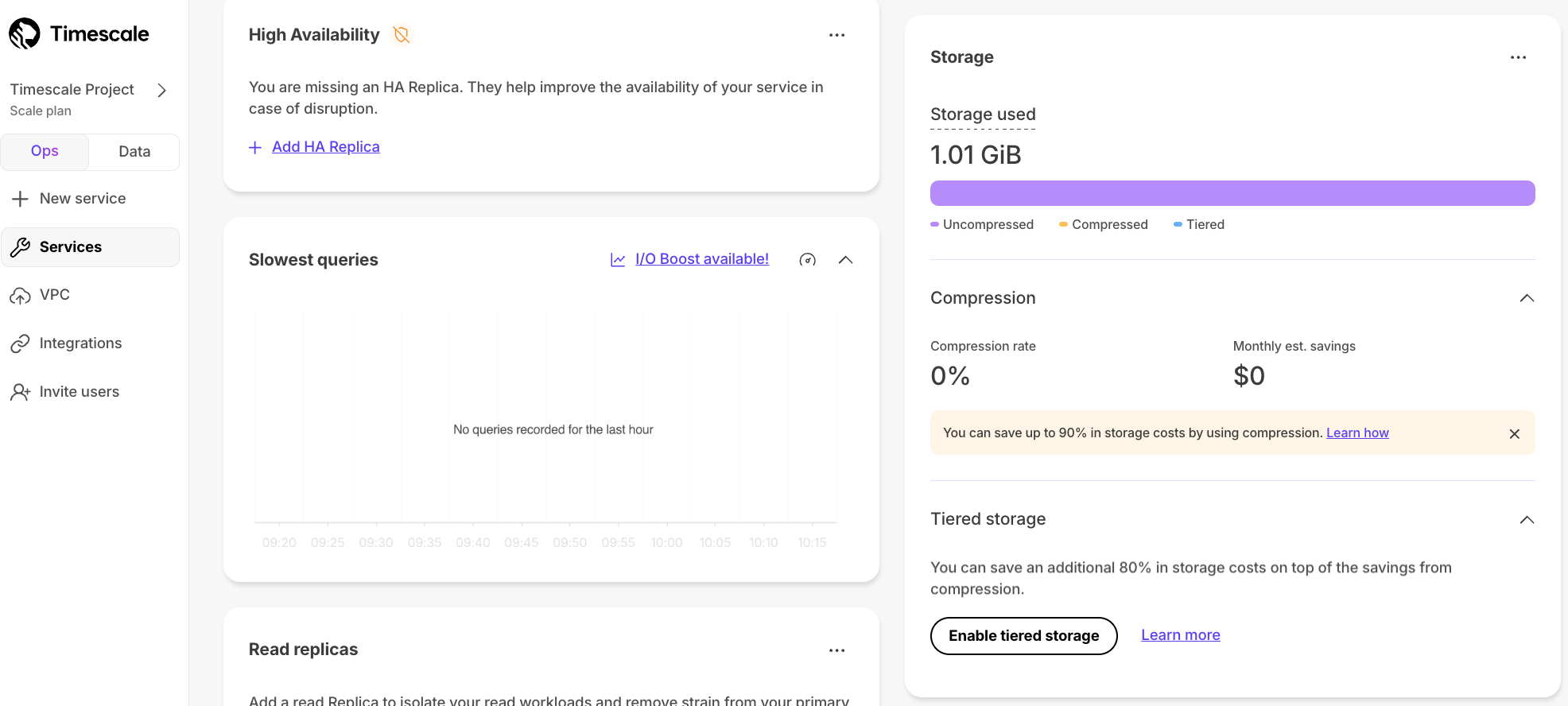
+
+ When tiered storage is enabled, you see the amount of data in the tiered object storage.
+
+1. **Set the time interval when data is tiered**
+
+ In $CONSOLE, click `SQL Editor`, then enable data tiering on a hypertable with the following query:
+ ```sql
+ SELECT add_tiering_policy('stock_candlestick_daily', INTERVAL '3 weeks');
+ ```
+
+1. **Qeury tiered data**
+
+ You enable reads from tiered data for each query, for a session or for all future
+ sessions. To run a single query on tiered data:
+
+ ```sql
+ set timescaledb.enable_tiered_reads = true; SELECT * FROM stocks_real_time srt LIMIT 10; set timescaledb.enable_tiered_reads = false;
+ ```
+ For more information, see [Querying tiered data][querying-tiered-data].
+
+
+
+## Reduce the risk of downtime and data loss with high availability
+
+By default, all $SERVICE_LONGs have rapid recovery enabled. However, if your app has very low tolerance
+for downtime, $CLOUD_LONG offers High Availability (HA) replicas. HA replicas are exact, up-to-date copies
+of your database hosted in multiple AWS availability zones (AZ) within the same region as your primary node.
+HA replicas automatically take over operations if the original primary data node becomes unavailable.
+The primary node streams its write-ahead log (WAL) to the replicas to minimize the chances of
+data loss during failover.
+
+High availability is available in the [scale and enterprise][pricing-plans] pricing plans for $CLOUD_LONG.
+
+
+
+For more information, see [High availability][high-availability].
+
+What next? See the [use case tutorials][tutorials], interact with the data in your $SERVICE_LONG using
+[your favorite programming language][connect-with-code], integrate your $SERVICE_LONG with a range of
+[third-party tools][integrations], plain old [Use Timescale][use-timescale], or dive into [the API][use-the-api].
+
+[tutorials]: /tutorials/:currentVersion:/
+[connect-with-code]: /quick-start/:currentVersion:/
+[integrations]: /use-timescale/:currentVersion:/integrations/
+[use-the-api]: /api/:currentVersion:/
+[use-timescale]: /use-timescale/:currentVersion:/
+
+[create-a-service]: /getting-started/:currentVersion:/services/
+[deploy-self-hosted]: /self-hosted/:currentVersion:/install/
+[connect-to-your-service]: /getting-started/:currentVersion:/run-queries-from-console/
+[portal-ops-mode]: https://console.cloud.timescale.com/dashboard/services
+[portal-data-mode]: https://console.cloud.timescale.com/dashboard/services?popsql
+[migrate-with-downtime]: /migrate/:currentVersion:/pg-dump-and-restore/
+[migrate-live]: /migrate/:currentVersion:/live-migration/
+[data-ingest]: /use-timescale/:currentVersion:/ingest-data/
+[hypertables-section]: /use-timescale/:currentVersion:/hypertables/
+[test-drive-enable-compression]: /getting-started/:currentVersion:/try-key-features-timescale-products/#prepare-your-data-for-real-time-analytics-with-hypercore
+[test-drive-tiered-storage]: /getting-started/:currentVersion:/try-key-features-timescale-products/#reduce-storage-charges-on-older-data-using-compression
+[data-tiering]: /use-timescale/:currentVersion:/data-tiering/
+[compression]: /use-timescale/:currentVersion:/compression/
+[hierarchical-caggs]: /use-timescale/:currentVersion:/continuous-aggregates/hierarchical-continuous-aggregates/
+[charts]: https://www.investopedia.com/terms/c/candlestick.asp
+[hierarchical-storage]: https://en.wikipedia.org/wiki/Hierarchical_storage_management
+[querying-tiered-data]: /use-timescale/:currentVersion:/data-tiering/querying-tiered-data/
+[data-tiering]: /use-timescale/:currentVersion:/data-tiering/
+[pricing-plans]: /about/:currentVersion:/pricing-and-account-management
+[querying-tiered-data]: /use-timescale/:currentVersion:/data-tiering/querying-tiered-data/
+[high-availability]: /use-timescale/:currentVersion:/ha-replicas/high-availability/
+[sign-up]: https://console.cloud.timescale.com/signup
+[job]: /api/:currentVersion:/actions/add_job/
+[add_columnstore_policy]: /api/:currentVersion:/hypercore/add_columnstore_policy/
diff --git a/lambda/redirects.js b/lambda/redirects.js
index 9b9d9bfdb1..8703531175 100644
--- a/lambda/redirects.js
+++ b/lambda/redirects.js
@@ -233,23 +233,23 @@ module.exports = [
},
{
from: "/getting-started/exploring-cloud",
- to: "https://docs.timescale.com/mst/latest/about-mst/",
+ to: "https://docs.timescale.com/getting-started/latest/try-key-features-timescale-products/",
},
{
from: "/getting-started/installation/timescale-cloud/installation-timescale-cloud",
- to: "https://docs.timescale.com/install/latest/installation-mst/",
+ to: "https://docs.timescale.com/getting-started/latest/try-key-features-timescale-products/",
},
{
from: "/getting-started/latest/add-data/",
- to: "https://docs.timescale.com/getting-started/latest/time-series-data/",
+ to: "https://docs.timescale.com/getting-started/latest/try-key-features-timescale-products/#optimize-time-series-data-in-hypertables",
},
{
- from: "/getting-started/latest/compress-data/",
- to: "https://docs.timescale.com/use-timescale/latest/compression/",
+ from: "/getting-started/latest/aggregation/",
+ to: "https://docs.timescale.com/getting-started/latest/try-key-features-timescale-products/#write-fast-analytical-queries-on-frequently-access-data-using-time-buckets-and-continuous-aggregates",
},
{
from: "/getting-started/latest/create-cagg/",
- to: "https://docs.timescale.com/getting-started/latest/aggregation/",
+ to: "https://docs.timescale.com/getting-started/latest/try-key-features-timescale-products/#write-fast-analytical-queries-on-frequently-access-data-using-time-buckets-and-continuous-aggregates",
},
{
from: "/getting-started/latest/data-retention",
@@ -264,8 +264,16 @@ module.exports = [
to: "https://docs.timescale.com/self-hosted/latest/install/installation-macos/",
},
{
- from: "/getting-started/latest/query-data/",
- to: "https://docs.timescale.com/getting-started/latest/queries/",
+ from: "/getting-started/latest/queries/",
+ to: "https://docs.timescale.com/getting-started/latest/try-key-features-timescale-products/#optimize-time-series-data-in-hypertables",
+ },
+ {
+ from: "/getting-started/latest/tables-hypertables/",
+ to: "https://docs.timescale.com/getting-started/latest/try-key-features-timescale-products/#optimize-time-series-data-in-hypertables",
+ },
+ {
+ from: "/getting-started/latest/time-series-data/",
+ to: "https://docs.timescale.com/getting-started/latest/try-key-features-timescale-products/#optimize-time-series-data-in-hypertables",
},
{
from: "/install/latest",
@@ -558,6 +566,22 @@ module.exports = [
from: "/tutorials/latest/aws-lambda/",
to: "https://docs.timescale.com/tutorials/latest/",
},
+ {
+ from: "/tutorials/latest/energy-data/",
+ to: "https://docs.timescale.com/tutorials/real-time-analytics-energy-consumption/",
+ },
+ {
+ from: "/tutorials/latest/energy-data/dataset-energy/",
+ to: "https://docs.timescale.com/tutorials/real-time-analytics-energy-consumption/",
+ },
+ {
+ from: "/tutorials/latest/energy-data/query-energy/",
+ to: "https://docs.timescale.com/tutorials/real-time-analytics-energy-consumption/",
+ },
+ {
+ from: "/tutorials/latest/energy-data/compress-energy/",
+ to: "https://docs.timescale.com/tutorials/real-time-analytics-energy-consumption/",
+ },
{
from: "/tutorials/latest/financial-candlestick-tick-data/create-candlestick-aggregates/",
to: "https://docs.timescale.com/tutorials/latest/financial-tick-data/financial-tick-query/",
@@ -578,6 +602,30 @@ module.exports = [
from: "/tutorials/latest/nfl-analytics/",
to: "https://docs.timescale.com/tutorials/latest/",
},
+ {
+ from: "/tutorials/latest/nyc-taxi-cab/",
+ to: "https://docs.timescale.com/tutorials/real-time-analytics-transport/",
+ },
+ {
+ from: "/tutorials/latest/nyc-taxi-cab/dataset-nyc/",
+ to: "https://docs.timescale.com/tutorials/real-time-analytics-transport/",
+ },
+ {
+ from: "/tutorials/latest/nyc-taxi-cab/query-nyc/",
+ to: "https://docs.timescale.com/tutorials/real-time-analytics-transport/",
+ },
+ {
+ from: "/tutorials/latest/nyc-taxi-cab/compress-nyc/",
+ to: "https://docs.timescale.com/tutorials/real-time-analytics-transport/",
+ },
+ {
+ from: "/tutorials/latest/nyc-taxi-geospatial/dataset-nyc/",
+ to: "https://docs.timescale.com/tutorials/real-time-analytics-transport/",
+ },
+ {
+ from: "/tutorials/latest/nyc-taxi-geospatial/plot-nyc",
+ to: "https://docs.timescale.com/tutorials/real-time-analytics-transport/",
+ },
{
from: "/tutorials/latest/prometheus-adapter/",
to: "https://docs.timescale.com/tutorials/latest/",
diff --git a/migrate/dual-write-and-backfill/dual-write-from-other.md b/migrate/dual-write-and-backfill/dual-write-from-other.md
index 9725cef8d4..be376ca5a6 100644
--- a/migrate/dual-write-and-backfill/dual-write-from-other.md
+++ b/migrate/dual-write-and-backfill/dual-write-from-other.md
@@ -79,7 +79,7 @@ continuous aggregate over the whole time range to ensure that there are no
holes in the aggregated data.
-[tables and hypertables]: /getting-started/:currentVersion:/tables-hypertables/
+[tables and hypertables]: /getting-started/:currentVersion:/try-key-features-timescale-products/#optimize-time-series-data-in-hypertables
@@ -137,4 +137,4 @@ your production workload.
-[dual-write-and-backfill]: /migrate/:currentVersion:/dual-write-and-backfill/
\ No newline at end of file
+[dual-write-and-backfill]: /migrate/:currentVersion:/dual-write-and-backfill/
diff --git a/migrate/dual-write-and-backfill/dual-write-from-postgres.md b/migrate/dual-write-and-backfill/dual-write-from-postgres.md
index 4299536479..5442383b1c 100644
--- a/migrate/dual-write-and-backfill/dual-write-from-postgres.md
+++ b/migrate/dual-write-and-backfill/dual-write-from-postgres.md
@@ -130,7 +130,7 @@ features, such as:
- [compression] to reduce the size of your hypertables
- [continuous aggregates] to write blisteringly fast aggregate queries on your data
-[time-series data]: /getting-started/:currentVersion:/time-series-data/
+[time-series data]: /getting-started/:currentVersion:/try-key-features-timescale-products/#optimize-time-series-data-in-hypertables
[create_table API reference]: /api/:currentVersion:/hypertable/create_hypertable/
[hypertable documentation]: /use-timescale/:currentVersion:/hypertables/
[retention policies]: /use-timescale/:currentVersion:/data-retention/
diff --git a/self-hosted/multinode-timescaledb/index.md b/self-hosted/multinode-timescaledb/index.md
index 600e990e7e..6b18cdd3ed 100644
--- a/self-hosted/multinode-timescaledb/index.md
+++ b/self-hosted/multinode-timescaledb/index.md
@@ -32,4 +32,4 @@ giving you faster data ingest, and more responsive and efficient queries.
[multi-node-grow-shrink]: /self-hosted/:currentVersion:/multinode-timescaledb/multinode-grow-shrink/
[multi-node-ha]: /self-hosted/:currentVersion:/multinode-timescaledb/multinode-ha/
[multi-node-maintenance]: /self-hosted/:currentVersion:/multinode-timescaledb/multinode-maintenance/
-[setup-selfhosted]: /self-hosted/:currentVersion:/multinode-timescaledb/multinode-setup/
\ No newline at end of file
+[setup-selfhosted]: /self-hosted/:currentVersion:/multinode-timescaledb/multinode-setup/
diff --git a/tutorials/OLD_grafana/visualizations/pie-chart.md b/tutorials/OLD_grafana/visualizations/pie-chart.md
index 41268df2c4..d7c8ef0656 100644
--- a/tutorials/OLD_grafana/visualizations/pie-chart.md
+++ b/tutorials/OLD_grafana/visualizations/pie-chart.md
@@ -166,4 +166,4 @@ Pie charts are a great tool for comparing categorized data. They're especially g
for visualizing percentages. But they don't work as well if you have too many categories
with similar percentages or large amount of data.
-[gsg-data]: https://docs.timescale.com/getting-started/latest/time-series-data/
+[gsg-data]: https://docs.timescale.com/getting-started/latest/try-key-features-timescale-products/#optimize-time-series-data-in-hypertables
diff --git a/tutorials/blockchain-analyze/blockchain-dataset.md b/tutorials/blockchain-analyze/blockchain-dataset.md
index 0c1189424f..d57ceeb7f1 100644
--- a/tutorials/blockchain-analyze/blockchain-dataset.md
+++ b/tutorials/blockchain-analyze/blockchain-dataset.md
@@ -7,43 +7,14 @@ layout_components: [next_prev_large]
content_group: Analyze the Bitcoin blockchain
---
-import CreateAndConnect from "versionContent/_partials/_cloud-create-connect-tutorials.mdx";
-import CreateHypertableBlockchain from "versionContent/_partials/_create-hypertable-blockchain.mdx";
-import AddDataBlockchain from "versionContent/_partials/_add-data-blockchain.mdx";
+import IngestData from "versionContent/_partials/_use-case-setup-blockchain-dataset.mdx";
import GrafanaConnect from "versionContent/_partials/_grafana-connect.mdx";
-# Set up the database
-
-This tutorial uses a dataset that contains Bitcoin blockchain data for
-the past five days, in a hypertable named `transactions`.
-
-
-
-
-
-
-
-
-
-The dataset contains around 1.5 million Bitcoin transactions, the trades for five days. It includes
-information about each transaction, along with the value in [satoshi][satoshi-def]. It also states if a
-trade is a [coinbase][coinbase-def] transaction, and the reward a coin miner receives for mining the coin.
-
-
-
-
-
-
-
-
-
-The queries in this tutorial are suitable for graphing in Grafana. If you want
-to visualize the results of your queries, connect your Grafana account to the
-Bitcoin blockchain dataset.
+
-
+
[satoshi-def]: https://www.pcmag.com/encyclopedia/term/satoshi
[coinbase-def]: https://www.pcmag.com/encyclopedia/term/coinbase-transaction
diff --git a/tutorials/blockchain-analyze/index.md b/tutorials/blockchain-analyze/index.md
index 7aee648ba8..35b6f0550a 100644
--- a/tutorials/blockchain-analyze/index.md
+++ b/tutorials/blockchain-analyze/index.md
@@ -7,16 +7,19 @@ layout_components: [next_prev_large]
content_group: Analyze the Bitcoin blockchain
---
+import FinancialIndustry from "versionContent/_partials/_financial-industry-data-analysis.mdx";
+
# Analyze the Bitcoin blockchain
-[Blockchains][blockchain-def] are, at their essence, a distributed database. The
-[transactions][transactions-def] in a blockchain are an example of time-series
-data. You can use Timescale to query transactions on a blockchain, in exactly the
-same way as you might query time-series transactions in any other database.
+
-In this tutorial, you use Timescale hyperfunctions to analyze transactions
-on the Bitcoin blockchain. You can use these instructions to query any type of data on a
-blockchain, including other cryptocurrencies, smart contracts, or health data.
+In this tutorial, you use Timescale to ingest, store, and analyze transactions
+on the Bitcoin blockchain.
+
+[Blockchains][blockchain-def] are, at their essence, a distributed database. The
+[transactions][transactions-def] in a blockchain are an example of time-series data. You can use
+Timescale to query transactions on a blockchain, in exactly the same way as you
+might query time-series transactions in any other database.
## Prerequisites
diff --git a/tutorials/blockchain-query/blockchain-dataset.md b/tutorials/blockchain-query/blockchain-dataset.md
index d19b09a721..76033d0afd 100644
--- a/tutorials/blockchain-query/blockchain-dataset.md
+++ b/tutorials/blockchain-query/blockchain-dataset.md
@@ -7,32 +7,7 @@ layout_components: [next_prev_large]
content_group: Query the Bitcoin blockchain
---
-import CreateAndConnect from "versionContent/_partials/_cloud-create-connect-tutorials.mdx";
-import CreateHypertableBlockchain from "versionContent/_partials/_create-hypertable-blockchain.mdx";
-import AddDataBlockchain from "versionContent/_partials/_add-data-blockchain.mdx";
+import IngestData from "versionContent/_partials/_use-case-setup-blockchain-dataset.mdx";
-# Set up the database
-This tutorial uses a dataset that contains Bitcoin blockchain data for
-the past five days, in a hypertable named `transactions`.
-
-
-
-
-
-
-
-
-
-The dataset contains around 1.5 million Bitcoin transactions, the trades for five days. It includes
-information about each transaction, along with the value in [satoshi][satoshi-def]. It also states if a
-trade is a [coinbase][coinbase-def] transaction, and the reward a coin miner receives for mining the coin.
-
-
-
-
-
-
-
-[satoshi-def]: https://www.pcmag.com/encyclopedia/term/satoshi
-[coinbase-def]: https://www.pcmag.com/encyclopedia/term/coinbase-transaction
+
diff --git a/tutorials/blockchain-query/index.md b/tutorials/blockchain-query/index.md
index 133f10cb5d..159f3da678 100644
--- a/tutorials/blockchain-query/index.md
+++ b/tutorials/blockchain-query/index.md
@@ -7,17 +7,20 @@ layout_components: [next_prev_large]
content_group: Query the Bitcoin blockchain
---
+import FinancialIndustry from "versionContent/_partials/_financial-industry-data-analysis.mdx";
+
# Query the Bitcoin blockchain
+
+
+In this tutorial, you use Timescale to ingest, store, and analyze transactions
+on the Bitcoin blockchain.
+
[Blockchains][blockchain-def] are, at their essence, a distributed database. The
[transactions][transactions-def] in a blockchain are an example of time-series data. You can use
Timescale to query transactions on a blockchain, in exactly the same way as you
might query time-series transactions in any other database.
-In this tutorial, you use Timescale to ingest, store, and analyze transactions
-on the Bitcoin blockchain. You can use these skills to query any data on a
-blockchain, including other cryptocurrencies, smart contracts, or health data.
-
## Prerequisites
Before you begin, make sure you have:
diff --git a/tutorials/energy-data/dataset-energy.md b/tutorials/energy-data/dataset-energy.md
index 812b5fa05b..88f1b3e095 100644
--- a/tutorials/energy-data/dataset-energy.md
+++ b/tutorials/energy-data/dataset-energy.md
@@ -8,115 +8,35 @@ layout_components: [next_prev_large]
content_group: Analyze energy consumption data
---
-import CreateAndConnect from "versionContent/_partials/_cloud-create-connect-tutorials.mdx";
+import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
import CreateHypertableEnergy from "versionContent/_partials/_create-hypertable-energy.mdx";
import AddDataEnergy from "versionContent/_partials/_add-data-energy.mdx";
import GrafanaConnect from "versionContent/_partials/_grafana-connect.mdx";
import CreateCaggs from "versionContent/_partials/_caggs-intro.mdx";
+import CreateCaggsOnIOTData from "versionContent/_partials/_use-case-iot-create-cagg.mdx";
-# Set up the database
+# Ingest data into a $SERVICE_LONG
This tutorial uses the energy consumption data for over a year in a
hypertable named `metrics`.
-
+## Prerequisites
-
-
-
-
-
-
-This tutorial uses the energy consumption data for over a year in a typical
-household. You can use this data to analyze the energy consumption pattern.
+
-
-
-
+## Create continuous aggregates
-## Create continuous aggregates
-
-### Creating continuous aggregates for energy consumption by day and hour
-
-1. Create a continuous aggregate `kwh_day_by_day` for energy consumption on a
- day to day basis:
-
- ```sql
- CREATE MATERIALIZED VIEW kwh_day_by_day(time, value)
- with (timescaledb.continuous) as
- SELECT time_bucket('1 day', created, 'Europe/Berlin') AS "time",
- round((last(value, created) - first(value, created)) * 100.) / 100. AS value
- FROM metrics
- WHERE type_id = 5
- GROUP BY 1;
- ```
-
-1. Add a refresh policy to keep the continuous aggregate up-to-date:
-
- ```sql
- SELECT add_continuous_aggregate_policy('kwh_day_by_day',
- start_offset => NULL,
- end_offset => INTERVAL '1 hour',
- schedule_interval => INTERVAL '1 hour');
- ```
-
-1. Create a continuous aggregate `kwh_hour_by_hour` for energy consumption on
- an hourly basis:
-
- ```sql
- CREATE MATERIALIZED VIEW kwh_hour_by_hour(time, value)
- with (timescaledb.continuous) as
- SELECT time_bucket('01:00:00', metrics.created, 'Europe/Berlin') AS "time",
- round((last(value, created) - first(value, created)) * 100.) / 100. AS value
- FROM metrics
- WHERE type_id = 5
- GROUP BY 1;
- ```
-
-1. Add a refresh policy to keep the continuous aggregate up-to-date:
-
- ```sql
- SELECT add_continuous_aggregate_policy('kwh_hour_by_hour',
- start_offset => NULL,
- end_offset => INTERVAL '1 hour',
- schedule_interval => INTERVAL '1 hour');
- ```
-
-1. You can confirm that the continuous aggregates were created:
-
- ```sql
- SELECT view_name, format('%I.%I', materialization_hypertable_schema,materialization_hypertable_name) AS materialization_hypertable
- FROM timescaledb_information.continuous_aggregates;
- ```
-
- You should see this:
-
- ```sql
- view_name | materialization_hypertable
- ------------------+--------------------------------------------------
- kwh_day_by_day | _timescaledb_internal._materialized_hypertable_2
- kwh_hour_by_hour | _timescaledb_internal._materialized_hypertable_3
-
- ```
+
-
-
-
-
-The queries in this tutorial are suitable for visualizing in Grafana. If you
-want to visualize the results of your queries, connect your Grafana account to
-the energy consumption dataset.
-
-
diff --git a/tutorials/energy-data/index.md b/tutorials/energy-data/index.md
index f951d215c7..52eb4d4a46 100644
--- a/tutorials/energy-data/index.md
+++ b/tutorials/energy-data/index.md
@@ -10,15 +10,13 @@ content_group: Analyze energy consumption data
# Analyze energy consumption data
-When you are planning to switch to a rooftop solar system it isn't easy, even
+When you are planning to switch to a rooftop solar system, it isn't easy, even
with a specialist at hand. You need details of your power consumption, typical
-usage hours, or distribution over a year. Collecting consumption data at the
-granularity of a few seconds is key to finding all the answers for more
-precision. This tutorial uses energy consumption data from a typical household
-for over a year. Because nearly all of this data is time-series data, proper
-analysis requires a purpose-built time-series database, like Timescale.
+usage hours, distribution over a year, and other information. Collecting consumption data at the
+granularity of a few seconds and then getting insights on it is key - and this is what Timescale is best at.
-In this tutorial you can construct queries that look at how many watts were
+This tutorial uses energy consumption data from a typical household
+for over a year. You construct queries that look at how many watts were
consumed, and when. Additionally, you can visualize the energy consumption data
in Grafana.
diff --git a/tutorials/financial-ingest-real-time/financial-ingest-dataset.md b/tutorials/financial-ingest-real-time/financial-ingest-dataset.md
index d75ba5fe11..0997c010b8 100644
--- a/tutorials/financial-ingest-real-time/financial-ingest-dataset.md
+++ b/tutorials/financial-ingest-real-time/financial-ingest-dataset.md
@@ -8,40 +8,36 @@ layout_components: [next_prev_large]
content_group: Ingest real-time financial websocket data
---
-import CreateAndConnect from "versionContent/_partials/_cloud-create-connect-tutorials.mdx";
+import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
import CreateHypertable from "versionContent/_partials/_create-hypertable-twelvedata-stocks.mdx";
-import CreateHypertableStocks from "versionContent/_partials/_create-hypertable-twelvedata-stocks.mdx";
+import CreateHypertableCrypo from "versionContent/_partials/_create-hypertable-twelvedata-crypto.mdx";
import GrafanaConnect from "versionContent/_partials/_grafana-connect.mdx";
-# Set up the database
+# Ingest data into a $SERVICE_LONG
This tutorial uses a dataset that contains second-by-second stock-trade data for
the top 100 most-traded symbols, in a hypertable named `stocks_real_time`. It
also includes a separate table of company symbols and company names, in a
regular PostgreSQL table named `company`.
-
+## Prerequisites
-
+
-
-
-
+## Connect to the websocket server
When you connect to the Twelve Data API through a websocket, you create a
persistent connection between your computer and the websocket server.
You set up a Python environment, and pass two arguments to create a
websocket object and establish the connection.
-## Set up a new Python environment
+### Set up a new Python environment
Create a new Python virtual environment for this project and activate it. All
the packages you need to complete for this tutorial are installed in this environment.
-### Setting up a new Python environment
-
1. Create and activate a Python virtual environment:
```bash
@@ -67,13 +63,13 @@ the packages you need to complete for this tutorial are installed in this enviro
-## Create the websocket connection
+### Create the websocket connection
A persistent connection between your computer and the websocket server is used
to receive data for as long as the connection is maintained. You need to pass
two arguments to create a websocket object and establish connection.
-### Websocket arguments
+#### Websocket arguments
* `on_event`
@@ -99,7 +95,7 @@ two arguments to create a websocket object and establish connection.
-### Connecting to the websocket server
+### Connect to the websocket server
1. Create a new Python file called `websocket_test.py` and connect to the
Twelve Data servers using the ``:
@@ -163,22 +159,8 @@ two arguments to create a websocket object and establish connection.
-
-
-
-
-To ingest the data into your Timescale service, you need to implement the
-`on_event` function.
-
-After the websocket connection is set up, you can use the `on_event` function
-to ingest data into the database. This is a data pipeline that ingests real-time
-financial data into your Timescale service.
-
-Stock trades are ingested in real-time Monday through Friday, typically during
-normal trading hours of the New York Stock Exchange (9:30 AM to
-4:00 PM EST).
-
+
When you ingest data into a transactional database like Timescale, it is more
efficient to insert data in batches rather than inserting data row-by-row. Using
@@ -195,6 +177,13 @@ universal, but you can experiment with different batch sizes
Using batching is a fairly common pattern when ingesting data into TimescaleDB
from Kafka, Kinesis, or websocket connections.
+To ingest the data into your Timescale service, you need to implement the
+`on_event` function.
+
+After the websocket connection is set up, you can use the `on_event` function
+to ingest data into the database. This is a data pipeline that ingests real-time
+financial data into your Timescale service.
+
You can implement a batching solution in Python with Psycopg2.
You can implement the ingestion logic within the `on_event` function that
you can then pass over to the websocket object.
@@ -207,7 +196,7 @@ This function needs to:
1. Add it to the in-memory batch, which is a list in Python.
1. If the batch reaches a certain size, insert the data, and reset or empty the list.
-## Ingesting data in real-time
+## Ingest data in real-time
@@ -323,17 +312,8 @@ If you see an error message similar to this:
Then check that you use a proper API key received from Twelve Data.
-
-
-
-
-The queries in this tutorial are suitable for visualizing in Grafana. If you
-want to visualize the results of your queries, connect your Grafana account to
-the energy consumption dataset.
-
-
[twelve-wrapper]: https://github.com/twelvedata/twelvedata-python
[psycopg2]: https://www.psycopg.org/docs/
diff --git a/tutorials/financial-ingest-real-time/financial-ingest-query.md b/tutorials/financial-ingest-real-time/financial-ingest-query.md
index 116668b4ea..c24909c34c 100644
--- a/tutorials/financial-ingest-real-time/financial-ingest-query.md
+++ b/tutorials/financial-ingest-real-time/financial-ingest-query.md
@@ -38,7 +38,7 @@ the last two hours' worth of data.
MIN(price) AS low,
LAST(price, time) AS "close",
LAST(day_volume, time) AS day_volume
- FROM stocks_real_time
+ FROM crypto_ticks
GROUP BY bucket, symbol;
```
diff --git a/tutorials/financial-ingest-real-time/index.md b/tutorials/financial-ingest-real-time/index.md
index cff6156daf..8b7231c798 100644
--- a/tutorials/financial-ingest-real-time/index.md
+++ b/tutorials/financial-ingest-real-time/index.md
@@ -1,5 +1,5 @@
---
-title: Ingest real-time financial websocket data
+title: Ingest real-time financial data using WebSocket
excerpt: Ingest time-series data into Timescale Cloud using a websocket connection
products: [cloud]
keywords: [finance, analytics, websockets, data pipeline]
@@ -9,8 +9,11 @@ content_group: Ingest real-time financial websocket data
---
import CandlestickIntro from "versionContent/_partials/_candlestick_intro.mdx";
+import FinancialIndustry from "versionContent/_partials/_financial-industry-data-analysis.mdx";
-# Ingest real-time financial websocket data
+# Ingest real-time financial data using WebSocket
+
+
This tutorial shows you how to ingest real-time time-series data into
TimescaleDB using a websocket connection. The tutorial sets up a data pipeline
diff --git a/tutorials/financial-tick-data/financial-tick-compress.md b/tutorials/financial-tick-data/financial-tick-compress.md
index e8493cd746..d4f29c8388 100644
--- a/tutorials/financial-tick-data/financial-tick-compress.md
+++ b/tutorials/financial-tick-data/financial-tick-compress.md
@@ -49,7 +49,7 @@ memory.
order-by column using the `ALTER TABLE` command:
```sql
- ALTER TABLE stocks_real_time
+ ALTER TABLE crypto_ticks
SET (
timescaledb.compress,
timescaledb.compress_segmentby='symbol',
@@ -64,7 +64,7 @@ memory.
`compress_chunk` in this manner:
```sql
- SELECT compress_chunk(c) from show_chunks('stocks_real_time') c;
+ SELECT compress_chunk(c) from show_chunks('crypto_ticks') c;
```
You can also [automate compression][automatic-compression] by
adding a [compression policy][add_compression_policy] which will
@@ -76,7 +76,7 @@ memory.
SELECT
pg_size_pretty(before_compression_total_bytes) as before,
pg_size_pretty(after_compression_total_bytes) as after
- FROM hypertable_compression_stats('stocks_real_time');
+ FROM hypertable_compression_stats('crypto_ticks');
```
This shows a significant improvement in data usage:
@@ -97,7 +97,7 @@ allows you to compress data that is older than a particular age, for
example, to compress all chunks that are older than 8 days:
```sql
-SELECT add_compression_policy('stocks_real_time', INTERVAL '8 days');
+SELECT add_compression_policy('crypto_ticks', INTERVAL '8 days');
```
Compression policies run on a regular schedule, by default once every
@@ -141,7 +141,7 @@ timing query times in psql by running:
To decompress the whole dataset, run:
```sql
- SELECT decompress_chunk(c) from show_chunks('stocks_real_time') c;
+ SELECT decompress_chunk(c) from show_chunks('crypto_ticks') c;
```
On an example setup, speedup performance observed was significant,
diff --git a/tutorials/financial-tick-data/financial-tick-dataset.md b/tutorials/financial-tick-data/financial-tick-dataset.md
index d654ae50bc..d6dab2ce25 100644
--- a/tutorials/financial-tick-data/financial-tick-dataset.md
+++ b/tutorials/financial-tick-data/financial-tick-dataset.md
@@ -8,42 +8,28 @@ layout_components: [next_prev_large]
content_group: Analyze financial tick data
---
-import CreateAndConnect from "versionContent/_partials/_cloud-create-connect-tutorials.mdx";
-import CreateHypertable from "versionContent/_partials/_create-hypertable-twelvedata-stocks.mdx";
-import AddData from "versionContent/_partials/_add-data-twelvedata-stocks.mdx";
+import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
+import CreateHypertableCrypto from "versionContent/_partials/_create-hypertable-twelvedata-crypto.mdx";
+import AddDataCrypto from "versionContent/_partials/_add-data-twelvedata-crypto.mdx";
+import GrafanaConnect from "versionContent/_partials/_grafana-connect.mdx";
-# Set up the database
+# Ingest data into a $SERVICE_LONG
-This tutorial uses a dataset that contains second-by-second stock-trade data for
-the top 100 most-traded symbols, in a hypertable named `stocks_real_time`. It
-also includes a separate table of company symbols and company names, in a
-regular PostgreSQL table named `company`.
-
-
-
-
-
-
-
-
+This tutorial uses a dataset that contains second-by-second trade data for
+the most-traded crypto-assets. You optimize this time-series data in a a hypertable called `assets_real_time`.
+You also create a separate table of asset symbols in a regular PostgreSQL table named `assets`.
The dataset is updated on a nightly basis and contains data from the last four
-weeks, typically around 8 million rows of data. Stock trades are recorded in
-real-time Monday through Friday, typically during normal trading hours of the
-New York Stock Exchange (9:30 AM - 4:00 PM EST).
-
-
+weeks, typically around 8 million rows of data. Trades are recorded in
+real-time from 180+ cryptocurrency exchanges.
-
+## Prerequisites
-
+
-
+
-The queries in this tutorial are suitable for visualizing in Grafana. If you
-want to visualize the results of your queries, connect your Grafana account to
-the energy consumption dataset.
+
-
diff --git a/tutorials/financial-tick-data/financial-tick-query.md b/tutorials/financial-tick-data/financial-tick-query.md
index 1fa9f7b78d..8a71337c50 100644
--- a/tutorials/financial-tick-data/financial-tick-query.md
+++ b/tutorials/financial-tick-data/financial-tick-query.md
@@ -61,7 +61,7 @@ the last two days' worth of data.
MIN(price) AS low,
LAST(price, time) AS "close",
LAST(day_volume, time) AS day_volume
- FROM stocks_real_time
+ FROM crypto_ticks
GROUP BY bucket, symbol;
```
diff --git a/tutorials/financial-tick-data/index.md b/tutorials/financial-tick-data/index.md
index 4e9977980a..1d1764f6a6 100644
--- a/tutorials/financial-tick-data/index.md
+++ b/tutorials/financial-tick-data/index.md
@@ -8,9 +8,13 @@ layout_components: [next_prev_large]
content_group: Analyze financial tick data
---
+import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
import CandlestickIntro from "versionContent/_partials/_candlestick_intro.mdx";
+import FinancialIndustry from "versionContent/_partials/_financial-industry-data-analysis.mdx";
-# Analyze financial tick data with TimescaleDB
+# Analyze financial tick data
+
+
To analyze financial data, you can chart the open, high, low, close, and volume
(OHLCV) information for a financial asset. Using this data, you can create
@@ -24,25 +28,7 @@ aggregated data, and visualize the data in Grafana.
## Prerequisites
-Before you begin, make sure you have:
-
-* Signed up for a [free Timescale account][cloud-install].
-
-## Steps in this tutorial
-
-This tutorial covers:
-
-1. [Setting up your dataset][financial-tick-dataset]: Load data from
- [Twelve Data][twelve-data] into your TimescaleDB database.
-1. [Querying your dataset][financial-tick-query]: Create candlestick views, query
- the aggregated data, and visualize the data in Grafana.
-1. [Bonus: Store data efficiently][financial-tick-compress]: Learn how to store and query
-your financial tick data more efficiently using compression feature of Timescale.
-
- This tutorial shows you how to ingest real-time time-series data into a Timescale
- database. To create candlestick views, query the
- aggregated data, and visualize the data in Grafana, see the
- [ingest real-time websocket data section][advanced-websocket].
+
## About OHLCV data and candlestick charts
@@ -58,6 +44,23 @@ these stories from some Timescale community members:
* [How Messari uses data to open the cryptoeconomy to everyone][messari]
* [How I power a (successful) crypto trading bot with TimescaleDB][bot]
+## Steps in this tutorial
+
+This tutorial shows you how to ingest real-time time-series data into a Timescale
+database:
+
+1. [Setting up your dataset][financial-tick-dataset]: Load data from
+ [Twelve Data][twelve-data] into your TimescaleDB database.
+1. [Querying your dataset][financial-tick-query]: Create candlestick views, query
+ the aggregated data, and visualize the data in Grafana.
+1. [Bonus: Store data efficiently][financial-tick-compress]: Learn how to store and query
+your financial tick data more efficiently using compression feature of Timescale.
+
+
+To create candlestick views, query the aggregated data, and visualize the data in Grafana, see the
+[ingest real-time websocket data section][advanced-websocket].
+
+
[advanced-websocket]: /tutorials/:currentVersion:/financial-ingest-real-time/
[cloud-install]: /getting-started/:currentVersion:/#create-your-timescale-account
[financial-tick-dataset]: /tutorials/:currentVersion:/financial-tick-data/financial-tick-dataset/
diff --git a/tutorials/index.md b/tutorials/index.md
index 53adf0ac44..8f9ddbc881 100644
--- a/tutorials/index.md
+++ b/tutorials/index.md
@@ -9,14 +9,26 @@ products: [cloud, mst, self_hosted]
Timescale tutorials are designed to help you get up and running with Timescale
fast. They walk you through a variety of scenarios using example datasets, to
teach you how to construct interesting queries, find out what information your
-database has hidden in it, and even gives you options for visualizing and
+database has hidden in it, and even give you options for visualizing and
graphing your results.
-|🔐 Cryptocurrency|🔋 Energy|💰 Finance|🚘 Transport| 💡 IoT |
-|-|-|-|-|------------------------------------------------------------|
-|🟢 [Part 1][beginner-crypto]
Do your own research on the Bitcoin blockchain|🟢 [Part 1][beginner-energy]
Optimize your energy consumption for a rooftop solar PV system|🟢 [Part 1][beginner-finance]
Chart the trading highs and lows for your favorite stock|🟢 [Part 1][beginner-fleet]
Find out about taxi rides taken in and around NYC| 🟢 [Part 1][iot]
Simulate an IoT sensor dataset |
-|⭐ [Part 2][intermediate-crypto]
Discover the relationship between transactions, blocks, fees, and miner revenue|⭐ *Coming Soon!*|⭐ [Part 2][advanced-finance]
Use a websocket connection to visualize the trading highs and lows for your favorite stock|⭐ [Part 2][intermediate-fleet]
Map the longest taxi rides in NYC| |
+- **Real-time analytics**
+ - [Analytics on energy consumption][rta-energy]: make data-driven decisions using energy consumption data
+ - [Analytics on transport and geospatial data][rta-transport]: optimize profits using geospatial transport data
+- **Cryptocurrency**
+ - [Query the Bitcoin blockchain][beginner-crypto]: do your own research on the Bitcoin blockchain
+ - [Analyze the Bitcoin blockchain][intermediate-crypto]: discover the relationship between transactions, blocks, fees, and miner revenue
+- **Finance**
+ - [Analyze financial tick data][beginner-finance]: chart the trading highs and lows for your favorite stock
+ - [Ingest real-time financial data using WebSocket][advanced-finance]: use a websocket connection to visualize the trading highs and lows for your favorite stock
+- **IoT**
+ - [Simulate an IoT sensor dataset][iot]: simulate an IoT sensor dataset
+- **Cookbooks**
+ - [Timescale community cookbook][cookbooks]: suggestions from the TimescaleDB Community about how to resolve common issues.
+
+[rta-energy]: /tutorials/:currentVersion:/real-time-analytics-energy-consumption
+[rta-transport]: /tutorials/:currentVersion:/real-time-analytics-transport
[beginner-fleet]: /tutorials/:currentVersion:/nyc-taxi-cab/
[beginner-finance]: /tutorials/:currentVersion:/financial-tick-data/
[beginner-crypto]: /tutorials/:currentVersion:/blockchain-query/
@@ -25,3 +37,4 @@ graphing your results.
[intermediate-crypto]: /tutorials/:currentVersion:/blockchain-analyze/
[advanced-finance]: /tutorials/:currentVersion:/financial-ingest-real-time/
[iot]: /tutorials/:currentVersion:/simulate-iot-sensor-data/
+[cookbooks]: /tutorials/:currentVersion:/cookbook/
diff --git a/tutorials/ingest-real-time-websocket-data.md b/tutorials/ingest-real-time-websocket-data.md
index ce4f604d95..c06d4450df 100644
--- a/tutorials/ingest-real-time-websocket-data.md
+++ b/tutorials/ingest-real-time-websocket-data.md
@@ -1,5 +1,5 @@
---
-title: Ingest real-time financial websocket data
+title: Ingest real-time financial data using WebSocket
excerpt: Set up a data pipeline to get data from different financial APIs
products: [cloud, mst, self_hosted]
keywords: [finance, analytics, websockets, data pipeline]
@@ -8,7 +8,7 @@ keywords: [finance, analytics, websockets, data pipeline]
import CreateHypertableStocks from "versionContent/_partials/_create-hypertable-twelvedata-stocks.mdx";
import GraphOhlcv from "versionContent/_partials/_graphing-ohlcv-data.mdx";
-# Ingest real-time financial websocket data
+# Ingest real-time financial data using WebSocket
This tutorial shows you how to ingest real-time time-series data into
TimescaleDB using a websocket connection. The tutorial sets up a data pipeline
diff --git a/tutorials/nyc-taxi-cab/dataset-nyc.md b/tutorials/nyc-taxi-cab/dataset-nyc.md
index fceb651151..06219aaa41 100644
--- a/tutorials/nyc-taxi-cab/dataset-nyc.md
+++ b/tutorials/nyc-taxi-cab/dataset-nyc.md
@@ -11,31 +11,22 @@ import CreateAndConnect from "versionContent/_partials/_cloud-create-connect-tut
import CreateHypertableNyc from "versionContent/_partials/_create-hypertable-nyctaxis.mdx";
import AddDataNyc from "versionContent/_partials/_add-data-nyctaxis.mdx";
import PreloadedData from "versionContent/_partials/_preloaded-data.mdx";
+import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
-# Set up the database
-This tutorial uses a dataset that contains historical data from New York's
-yellow taxi network, in a hypertable named `rides`. It also includes a separate
+# Ingest data into a $SERVICE_LONG
+
+This tutorial uses a dataset that contains historical data from the New York City Taxi and Limousine
+Commission [NYC TLC][nyc-tlc], in a hypertable named `rides`. It also includes a separate
tables of payment types and rates, in a regular PostgreSQL table named
`payment_types`, and `rates`.
-
-
-
-
-
+## Prerequisites
-
-
-
-
-This tutorial uses historical data from New York's yellow taxi network, provided
-by the New York City Taxi and Limousine Commission [NYC TLC][nyc-tlc].
+
-
-
[nyc-tlc]: https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page
diff --git a/tutorials/nyc-taxi-geospatial/dataset-nyc.md b/tutorials/nyc-taxi-geospatial/dataset-nyc.md
index eb7e335897..8a6d82e93a 100644
--- a/tutorials/nyc-taxi-geospatial/dataset-nyc.md
+++ b/tutorials/nyc-taxi-geospatial/dataset-nyc.md
@@ -12,39 +12,25 @@ import CreateAndConnect from "versionContent/_partials/_cloud-create-connect-tut
import CreateHypertableNyc from "versionContent/_partials/_create-hypertable-nyctaxis.mdx";
import AddDataNyc from "versionContent/_partials/_add-data-nyctaxis.mdx";
import GrafanaConnect from "versionContent/_partials/_grafana-connect.mdx";
+import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
-# Set up the database
+# Ingest data into a $SERVICE_LONG
-This tutorial uses a dataset that contains historical data from New York's
-yellow taxi network, in a hypertable named `rides`. It also includes a separate
+This tutorial uses a dataset that contains historical data from the New York City Taxi and Limousine
+Commission [NYC TLC][nyc-tlc], in a hypertable named `rides`. It also includes a separate
tables of payment types and rates, in a regular PostgreSQL table named
`payment_types`, and `rates`.
-
+## Prerequisites
-
-
-
-
-
-
-This tutorial uses historical data from New York's yellow taxi network, provided
-by the New York City Taxi and Limousine Commission [NYC TLC][nyc-tlc].
+
-
-
-
-
-The queries in this tutorial are suitable for visualizing in Grafana. If you
-want to visualize the results of your queries, connect your Grafana account to
-the NYC taxi cab dataset.
-
-
+
[nyc-tlc]: https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page
diff --git a/tutorials/page-index/page-index.js b/tutorials/page-index/page-index.js
index 8b2281dca2..a8a77f25df 100644
--- a/tutorials/page-index/page-index.js
+++ b/tutorials/page-index/page-index.js
@@ -5,18 +5,38 @@ module.exports = [
excerpt: "Learn about common scenarios and use cases for Timescale",
children: [
{
- title: "Cryptocurrency - part 1",
+ title: "Analytics on transport and geospatial data",
+ href: "real-time-analytics-transport",
+ excerpt: "Analyse your data in real-time",
+ },
+ {
+ title: "Analytics on energy consumption",
+ href: "real-time-analytics-energy-consumption",
+ excerpt: "Analyse your data in real-time",
+ },
+ {
+ title: "Simulate an IoT sensor dataset",
+ href: "simulate-iot-sensor-data",
+ excerpt: "Simulate and query an IoT sensor dataset",
+ },
+ {
+ title: "Timescale community cookbook",
+ href: "cookbook",
+ excerpt: "Code examples from the community that help you with loads of common conundrums.",
+ },
+ {
+ title: "Query the Bitcoin blockchain",
href: "blockchain-query",
excerpt: "Query the Bitcoin blockchain",
children: [
{
- title: "Set up",
+ title: "Ingest data into a service",
href: "blockchain-dataset",
excerpt:
"Set up a dataset so you can query the Bitcoin blockchain",
},
{
- title: "Query data",
+ title: "Query the data",
href: "beginner-blockchain-query",
excerpt: "Query the Bitcoin blockchain dataset",
},
@@ -29,58 +49,35 @@ module.exports = [
],
},
{
- title: "Cryptocurrency - part 2",
+ title: "Analyze the Bitcoin blockchain",
href: "blockchain-analyze",
excerpt: "Analyze the Bitcoin blockchain with Timescale hyperfunctions",
children: [
{
- title: "Set up",
+ title: "Ingest data into a service",
href: "blockchain-dataset",
excerpt:
"Set up a dataset so you can analyze the Bitcoin blockchain",
},
{
- title: "Query data",
+ title: "Analyse the data",
href: "analyze-blockchain-query",
excerpt: "Analyze the Bitcoin blockchain dataset with Timescale hyperfunctions",
},
],
},
{
- title: "Energy - part 1",
- href: "energy-data",
- excerpt: "Learn how to analyze energy consumption data",
- children: [
- {
- title: "Set up",
- href: "dataset-energy",
- excerpt: "Set up a dataset so you can analyze energy consumption data",
- },
- {
- title: "Query data",
- href: "query-energy",
- excerpt: "Queries energy consumption data",
- },
- {
- title: "Bonus: set up compression",
- href: "compress-energy",
- excerpt:
- "Compress the dataset so you can store the data more efficiently",
- },
- ]
- },
- {
- title: "Finance - part 1",
+ title: "Analyze financial tick data ",
href: "financial-tick-data",
excerpt: "Use Timescale to store financial tick data",
children: [
{
- title: "Set up",
+ title: "Ingest data into a service",
href: "financial-tick-dataset",
excerpt: "Set up a dataset so you can query financial tick data",
},
{
- title: "Query data",
+ title: "Query the data",
href: "financial-tick-query",
excerpt: "Query and visualize financial tick data",
},
@@ -93,72 +90,22 @@ module.exports = [
],
},
{
- title: "Finance - part 2",
+ title: "Ingest real-time financial data",
href: "financial-ingest-real-time",
excerpt: "Ingest real-time financial data with websocket",
children: [
{
- title: "Set up",
+ title: "Ingest data into a service",
href: "financial-ingest-dataset",
excerpt: "Set up a dataset so you can query the real-time data",
},
{
- title: "Query data",
+ title: "Query the data",
href: "financial-ingest-query",
excerpt: "Query and visualize real-time data",
},
],
},
- {
- title: "Transport - part 1",
- href: "nyc-taxi-cab",
- excerpt: "An introduction to time-series using NYC taxi data",
- children: [
- {
- title: "Set up",
- href: "dataset-nyc",
- excerpt: "Set up a dataset so you can query NYC data",
- },
- {
- title: "Query data",
- href: "query-nyc",
- excerpt: "Query NYC data",
- },
- {
- title: "Bonus: set up compression",
- href: "compress-nyc",
- excerpt:
- "Compress the dataset so you can store the data more efficiently",
- },
- ],
- },
- {
- title: "Transport - part 2",
- href: "nyc-taxi-geospatial",
- excerpt: "Learn how to plot geospatial time-series data with NYC taxi cabs",
- children: [
- {
- title: "Set up",
- href: "dataset-nyc",
- excerpt: "Set up a dataset so you can plot geospatial NYC taxi data",
- },
- {
- title: "Query data",
- href: "plot-nyc",
- excerpt: "Plot geospatial NYC taxi data",
- },
- ],
- },
- {
- title: "Internet of things",
- href: "simulate-iot-sensor-data",
- excerpt: "Simulate and query an IoT sensor dataset",
- },
- {
- title: "Timescale community cookbook",
- href: "cookbook",
- excerpt: "Code examples from the community that help you with loads of common conundrums.",
- },
],
},
];
diff --git a/tutorials/real-time-analytics-energy-consumption.md b/tutorials/real-time-analytics-energy-consumption.md
new file mode 100644
index 0000000000..131763e73e
--- /dev/null
+++ b/tutorials/real-time-analytics-energy-consumption.md
@@ -0,0 +1,226 @@
+---
+title: Real-time analytics with Timescale Cloud and Grafana
+excerpt: Simulate an IOT dataset in your Timescale Cloud service
+products: [cloud, mst, self_hosted]
+keywords: [IoT, simulate]
+---
+
+
+import GrafanaConnect from "versionContent/_partials/_grafana-connect.mdx";
+import ImportDataEnergy from "versionContent/_partials/_import-data-iot.mdx";
+import CreateCaggsOnIOTData from "versionContent/_partials/_use-case-iot-create-cagg.mdx";
+import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
+
+# Analytics on energy consumption
+
+Energy providers understand that customers tend to lose patience when there is not enough power for them
+to complete day-to-day activities. Task one is keeping the lights on. If you are transitioning to renewable energy,
+it helps to know when you need to produce energy so you can choose a suitable energy source.
+
+Real-time analytics refers to the process of collecting, analyzing, and interpreting data instantly as it is generated.
+This approach enables you track and monitor activity, make the decisions based on real-time insights on data stored in
+a $SERVICE_LONG and keep those lights on.
+
+
+[Grafana][grafana-docs] is a popular data visualization tool that enables you to create customizable dashboards
+and effectively monitor your systems and applications.
+
+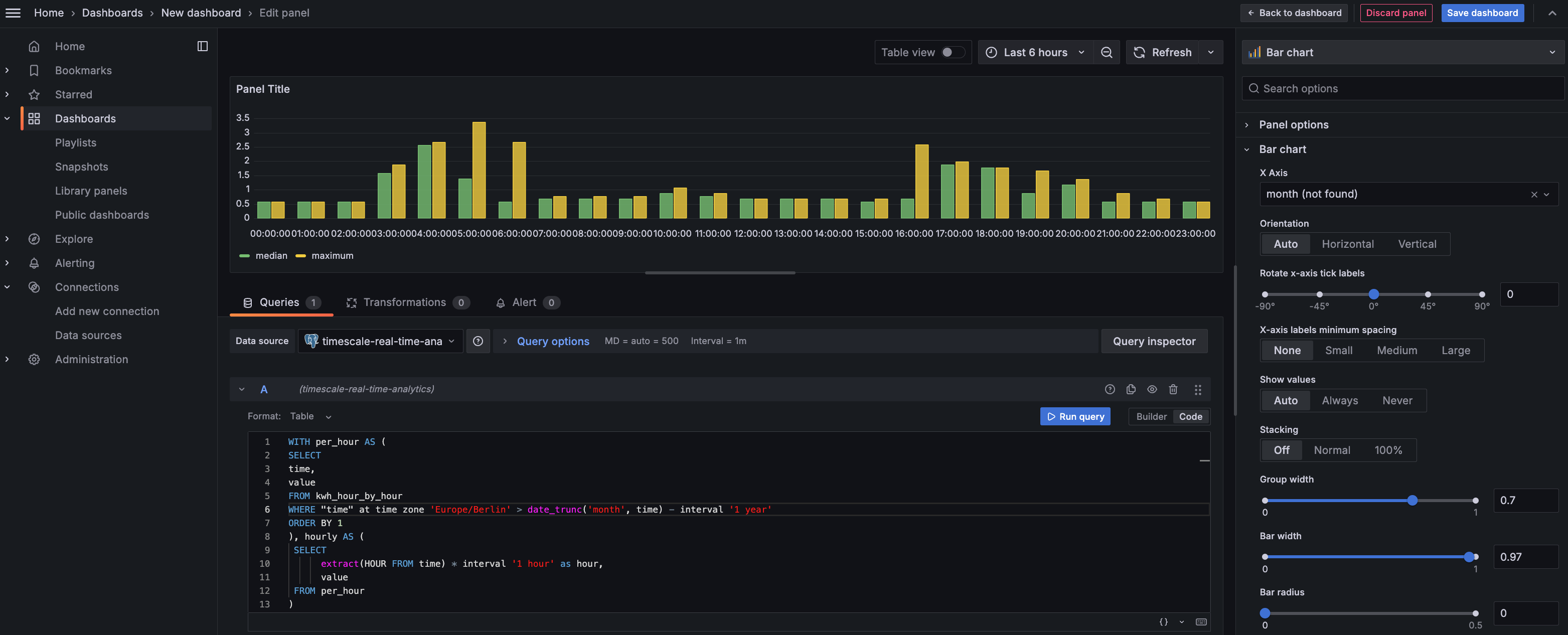
+
+This page shows you how to integrate Grafana with a $SERVICE_LONG and make insights based on visualization of
+data optimized for size and speed in the columnstore.
+
+## Prerequisites
+
+
+
+* Install and run [self-managed Grafana][grafana-self-managed], or sign up for [Grafana Cloud][grafana-cloud].
+
+## Optimize time-series data in hypertables
+
+
+
+## Write fast analytical queries
+
+Aggregation is a way of combing data to get insights from it. Average, sum, and count are all examples of simple
+aggregates. However, with large amounts of data aggregation slows things down, quickly. Continuous aggregates
+are a kind of hypertable that is refreshed automatically in the background as new data is added, or old data is
+modified. Changes to your dataset are tracked, and the hypertable behind the continuous aggregate is automatically
+updated in the background.
+
+By default, querying continuous aggregates provides you with real-time data. Pre-aggregated data from the materialized
+view is combined with recent data that hasn't been aggregated yet. This gives you up-to-date results on every query.
+
+You create continuous aggregates on uncompressed data in high-performance storage. They continue to work
+on [data in the columnstore][test-drive-enable-compression]
+and [rarely accessed data in tiered storage][test-drive-tiered-storage]. You can even
+create [continuous aggregates on top of your continuous aggregates][hierarchical-caggs].
+
+
+
+
+
+
+
+## Optimize your data for real-time analytics
+
+[Hypercore][hypercore] is the $COMPANY hybrid row-columnar storage engine used by hypertables. Hypertables partition your data in
+chunks. Chunks stored in the rowstore use a row-oriented data format optimized for high-speed inserts and updates.
+Chunks stored in the columnstore use a columnar data format optimized for analytics. You ingest `hot` data into the
+rowstore. As data cools and becomes more suited for analytics, $CLOUD_LONG automatically converts these chunks of data
+to the columnstore. You define the moment when data is converted using a columnstore policy.
+
+When $CLOUD_LONG converts a chunk to the columnstore, TimescaleDB automatically creates a different schema for your
+data. $TIMESCALE_DB creates and uses custom indexes to incorporate the `segmentby` and `orderby` parameters when
+you write to and read from the columstore.
+
+To increase the speed of your analytical queries by a factor of 10 and reduce storage costs by up to 90%, convert data
+to the columnstore:
+
+
+
+1. **Connect to your $SERVICE_LONG**
+
+ In [$CONSOLE][services-portal] open an [SQL editor][in-console-editors]. The in-console editors display the query speed.
+ You can also connect to your service using [psql][connect-using-psql].
+
+1. **Enable columnstore on a hypertable**
+
+ Create a [job][job] that automatically moves chunks in a hypertable to the columnstore at a specific time interval.
+ By default, your table is `orderedby` the time column. For efficient queries on columnstore data, remember to
+ `segmentby` the column you will use most often to filter your data:
+
+ ```sql
+ ALTER TABLE metrics SET (
+ timescaledb.enable_columnstore = true,
+ timescaledb.segmentby = 'type_id',
+ timescaledb.orderby = 'created DESC'
+ );
+ ```
+
+1. **Add a policy to convert chunks to the columnstore at a specific time interval**
+
+ For example, 60 days after the data was added to the table:
+ ``` sql
+ CALL add_columnstore_policy('metrics', INTERVAL '8 days');
+ ```
+ See [add_columnstore_policy][add_columnstore_policy].
+
+1. **View your data space saving**
+
+ When you convert data to the columnstore, as well as being optimized for analytics, it is compresses by more than 90%.
+ This saves on storage costs and keeps your queries operating at lightning speed. To see the amount of space saved:
+ ```sql
+ SELECT
+ pg_size_pretty(before_compression_total_bytes) as before,
+ pg_size_pretty(after_compression_total_bytes) as after
+ FROM hypertable_compression_stats('metrics');
+ ```
+ You see something like:
+
+ | before | after |
+ |--------|-------|
+ | 181 MB | 16 MB |
+
+1. **Faster analytical queries on data in the columnstore**
+
+ Now run the analytical query again:
+ ```sql
+ SELECT time_bucket('1 day', created, 'Europe/Berlin') AS "time",
+ round((last(value, created) - first(value, created)) * 100.) / 100. AS value
+ FROM metrics
+ WHERE type_id = 5
+ GROUP BY 1;
+ ```
+ On this amount of data, this analytical query on data in the columnstore takes about 0.8 seconds.
+
+
+
+Just to hit this one home, by converting cooling data to the columnstore, you have increase the speed of your analytical
+queries by a factor of 10, and reduced storage by up to 90%.
+
+
+
+## Visualize energy consumption
+
+A Grafana dashboard represents a view into the performance of a system, and each dashboard consists of one or
+more panels, which represent information about a specific metric related to that system.
+
+To visually monitor the volume of energy consumption over time:
+
+
+
+1. **Create the dashboard**
+
+ 1. On the `Dashboards` page, click `New` and select `New dashboard`.
+
+ 1. Click `Add visualization`, then select the data source that connects to your $SERVICE_LONG and the `Bar chart`
+ visualization.
+
+ 
+ 1. In the `Queries` section, select `Code`, then run the following query based on your continuous aggregate:
+
+ ```sql
+ WITH per_hour AS (
+ SELECT
+ time,
+ value
+ FROM kwh_hour_by_hour
+ WHERE "time" at time zone 'Europe/Berlin' > date_trunc('month', time) - interval '1 year'
+ ORDER BY 1
+ ), hourly AS (
+ SELECT
+ extract(HOUR FROM time) * interval '1 hour' as hour,
+ value
+ FROM per_hour
+ )
+ SELECT
+ hour,
+ approx_percentile(0.50, percentile_agg(value)) as median,
+ max(value) as maximum
+ FROM hourly
+ GROUP BY 1
+ ORDER BY 1;
+ ```
+
+ This query averages the results for households in a specific time zone by hour and orders them by time.
+ Because you use a continuous aggregate, this data is always correct in real-time.
+
+ 
+
+ You see that energy consumption is highest in the evening and at breakfast time. You also know that the wind
+ drops off in the evening. This data proves that you need to supply a supplementary power source for peak times,
+ or plan to store energy during the day for peak times.
+
+1. **Click `Save dashboard`**
+
+
+
+
+You have integrated Grafana with a Timescale Cloud service and made insights based on visualization of your data.
+
+[grafana-docs]: https://grafana.com/docs/
+[grafana-self-managed]: https://grafana.com/get/?tab=self-managed
+[grafana-cloud]: https://grafana.com/get/
+[use-time-buckets]: /use-timescale/:currentVersion:/time-buckets/use-time-buckets/
+
+[test-drive-enable-compression]: /getting-started/:currentVersion:/try-key-features-timescale-products/#prepare-your-data-for-real-time-analytics-with-hypercore
+[test-drive-tiered-storage]: /getting-started/:currentVersion:/try-key-features-timescale-products/#reduce-storage-charges-on-older-data-using-compression
+[data-tiering]: /use-timescale/:currentVersion:/data-tiering/
+[compression]: /use-timescale/:currentVersion:/compression/
+[hierarchical-caggs]: /use-timescale/:currentVersion:/continuous-aggregates/hierarchical-continuous-aggregates/
+[job]: /api/:currentVersion:/actions/add_job/
+[alter_table_hypercore]: /api/:currentVersion:/hypercore/alter_table/
+[compression_continuous-aggregate]: /api/:currentVersion:/hypercore/alter_materialized_view/
+[convert_to_rowstore]: /api/:currentVersion:/hypercore/convert_to_rowstore/
+[convert_to_columnstore]: /api/:currentVersion:/hypercore/convert_to_columnstore/
+[informational-views]: /api/:currentVersion:/informational-views/jobs/
+[add_columnstore_policy]: /api/:currentVersion:/hypercore/add_columnstore_policy/
+[hypercore_workflow]: /api/:currentVersion:/hypercore/#hypercore-workflow
+[alter_job]: /api/:currentVersion:/actions/alter_job/
+[remove_columnstore_policy]: /api/:currentVersion:/hypercore/remove_columnstore_policy/
+[in-console-editors]: /getting-started/:currentVersion:/run-queries-from-console/
+[services-portal]: https://console.cloud.timescale.com/dashboard/services
+[connect-using-psql]: /use-timescale/:currentVersion:/integrations/query-admin/psql#connect-to-your-service
+[insert]: /use-timescale/:currentVersion:/write-data/insert/
+[hypercore]: /use-timescale/:currentVersion:/hypercore/
diff --git a/tutorials/real-time-analytics-transport.md b/tutorials/real-time-analytics-transport.md
new file mode 100644
index 0000000000..a0f4a88e74
--- /dev/null
+++ b/tutorials/real-time-analytics-transport.md
@@ -0,0 +1,189 @@
+---
+title: Analytics on transport and geospatial data
+excerpt: Simulate and analyze a transport dataset in your Timescale Cloud service
+products: [cloud, mst, self_hosted]
+keywords: [IoT, simulate]
+---
+
+import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
+import GrafanaConnect from "versionContent/_partials/_grafana-connect.mdx";
+import ImportData from "versionContent/_partials/_import-data-nyc-taxis.mdx";
+import GeolocationAnalytics from "versionContent/_partials/_use-case-transport-geolocation.mdx";
+
+# Analytics on transport and geospatial data
+
+Real-time analytics refers to the process of collecting, analyzing, and interpreting data instantly as it
+is generated. This approach enables you track and monitor activity, and make decisions based on real-time
+insights on data stored in a $SERVICE_LONG.
+
+
+
+This page shows you how to integrate [Grafana][grafana-docs] with a $SERVICE_LONG and make insights based on visualization
+of data optimized for size and speed in the columnstore.
+
+## Prerequisites
+
+
+
+* Install and run [self-managed Grafana][grafana-self-managed], or sign up for [Grafana Cloud][grafana-cloud].
+
+## Optimize time-series data in hypertables
+
+
+
+## Optimize your data for real-time analytics
+
+[Hypercore][hypercore] is the $COMPANY hybrid row-columnar storage engine used by hypertables. Hypertables partition your data in
+chunks. Chunks stored in the rowstore use a row-oriented data format optimized for high-speed inserts and updates.
+Chunks stored in the columnstore use a columnar data format optimized for analytics. You ingest `hot` data into the
+rowstore. As data cools and becomes more suited for analytics, $CLOUD_LONG automatically converts these chunks of data
+to the columnstore. You define the moment when data is converted using a columnstore policy.
+
+When $CLOUD_LONG converts a chunk to the columnstore, TimescaleDB automatically creates a different schema for your
+data. $TIMESCALE_DB creates and uses custom indexes to incorporate the `segmentby` and `orderby` parameters when
+you write to and read from the columstore.
+
+To increase the speed of your analytical queries by a factor of 10 and reduce storage costs by up to 90%, convert data
+to the columnstore:
+
+
+
+1. **Connect to your $SERVICE_LONG**
+
+ In [$CONSOLE][services-portal] open an [SQL editor][in-console-editors]. The in-console editors display the query speed.
+ You can also connect to your service using [psql][connect-using-psql].
+
+1. **Enable columnstore on a hypertable**
+
+ Create a [job][job] that automatically moves chunks in a hypertable to the columnstore at a specific time interval.
+ By default, your table is `orderedby` the time column. For efficient queries on columnstore data, remember to
+ `segmentby` the column you will use most often to filter your data:
+
+ ```sql
+ ALTER TABLE rides SET (
+ timescaledb.enable_columnstore = true,
+ timescaledb.segmentby = 'vendor_id',
+ timescaledb.orderby = 'pickup_datetime DESC'
+ );
+ ```
+
+1. **Add a policy to convert chunks to the columnstore at a specific time interval**
+
+ For example, convert data older than 8 days old to the columstore:
+ ``` sql
+ CALL add_columnstore_policy('rides', INTERVAL '8 days');
+ ```
+ See [add_columnstore_policy][add_columnstore_policy].
+
+1. **View your data space saving**
+
+ When you convert data to the columnstore, as well as being optimized for analytics, it is compresses by more than 90%.
+ This saves on storage costs and keeps your queries operating at lightning speed. To see the amount of space saved:
+ ```sql
+ SELECT
+ pg_size_pretty(before_compression_total_bytes) as before,
+ pg_size_pretty(after_compression_total_bytes) as after
+ FROM hypertable_compression_stats('rides');
+ ```
+ You see something like:
+
+ | before | after |
+ |--|--|
+ |2818 MB | 673 MB |
+
+1. **Faster analytical queries on data in the columnstore**
+
+ Now run the analytical query again:
+ ```sql
+ SELECT rates.description, COUNT(vendor_id) AS num_trips
+ FROM rides
+ JOIN rates ON rides.rate_code = rates.rate_code
+ WHERE pickup_datetime < '2016-01-08'
+ GROUP BY rates.description
+ ORDER BY LOWER(rates.description);
+ ```
+ On this large amount of data, this analytical query on data in the columnstore takes about 6 seconds.
+
+
+
+Just to hit this one home, by converting cooling data to the columnstore, you have increase the speed of your analytical
+queries by a factor of 10, and reduced storage by up to 90%.
+
+
+
+
+## Monitor performance over time
+
+A Grafana dashboard represents a view into the performance of a system, and each dashboard consists of one or
+more panels, which represent information about a specific metric related to that system.
+
+To visually monitor the volume of taxi rides over time:
+
+
+
+1. **Create the dashboard**
+
+ 1. On the `Dashboards` page, click `New` and select `New dashboard`.
+
+ 1. Click `Add visualization`.
+ 1. Select the data source that connects to your $SERVICE_LONG.
+ The `Time series` visualization is chosen by default.
+ 
+ 1. In the `Queries` section, select `Code`, then select `Time series` in `Format`.
+ 1. Select the data range for your visualization:
+ the data set is from 2016. Click the date range above the panel and set:
+ - From: ```2016-01-01 01:00:00```
+ - To: ```2016-01-30 01:00:00```
+
+1. **Combine $TIMESCALE_DB and Grafana functionality to analyze your data**
+
+ Combine a $TIMESCALE_DB [time_bucket][use-time-buckets], with the Grafana `$__timefilter()` function to set the
+ `pickup_datetime` column as the filtering range for your visualizations.
+ ```sql
+ SELECT
+ time_bucket('1 day', pickup_datetime) AS "time",
+ COUNT(*)
+ FROM rides
+ WHERE $__timeFilter(pickup_datetime)
+ GROUP BY time
+ ORDER BY time;
+ ```
+ This query groups the results by day and orders them by time.
+
+ 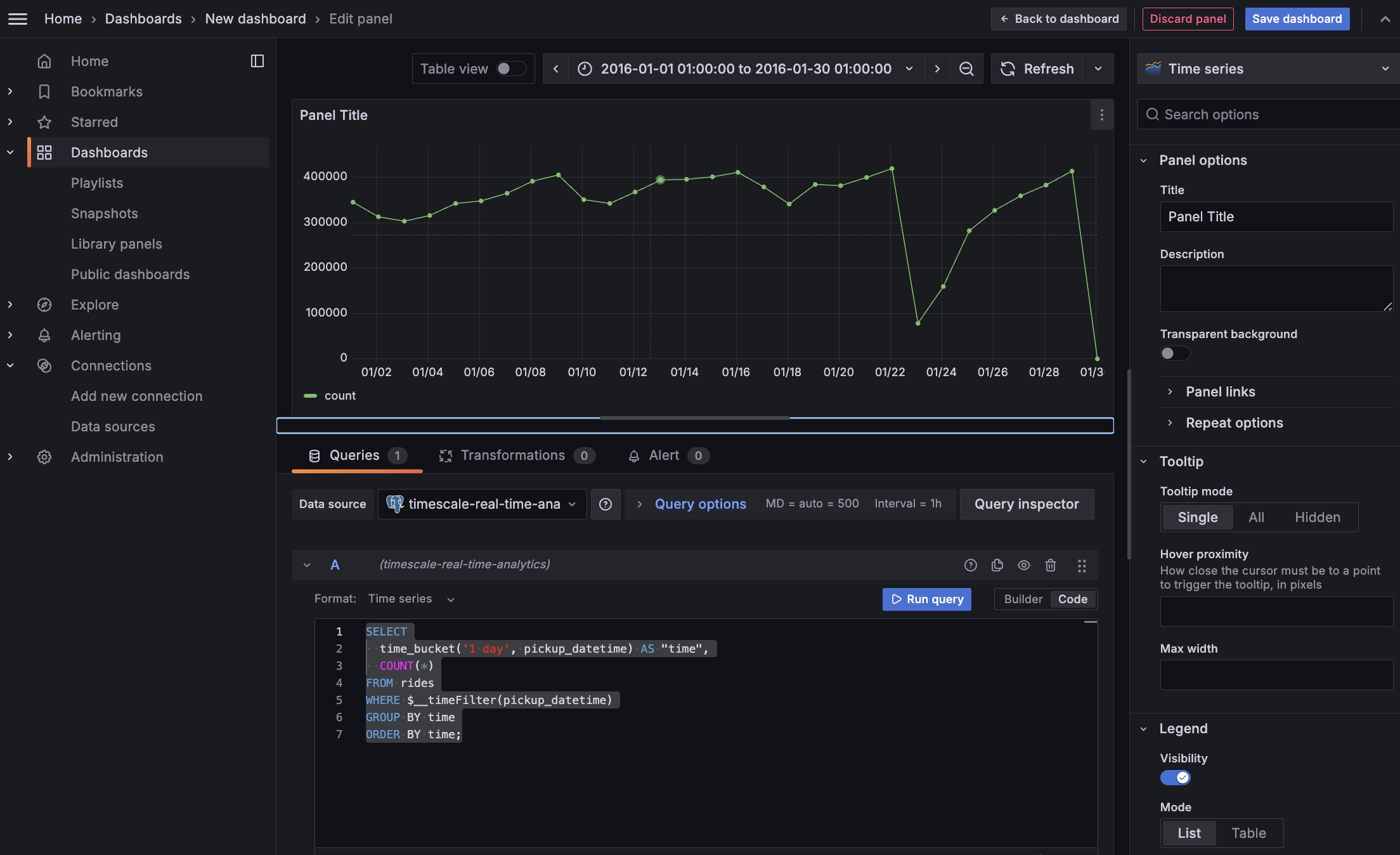
+
+1. **Click `Save dashboard`**
+
+
+
+
+## Optimize revenue potential
+
+Having all this data is great but how do you use it? Monitoring data is useful to check what
+has happened, but how can you analyse this information to your advantage? This section explains
+how to create a visualization that shows how you can maximize potential revenue.
+
+
+
+You have integrated Grafana with a $SERVICE_LONG and made insights based on visualization of
+your data.
+
+[grafana-docs]: https://grafana.com/docs/
+[grafana-self-managed]: https://grafana.com/get/?tab=self-managed
+[grafana-cloud]: https://grafana.com/get/
+[use-time-buckets]: /use-timescale/:currentVersion:/time-buckets/use-time-buckets/
+[job]: /api/:currentVersion:/actions/add_job/
+[alter_table_hypercore]: /api/:currentVersion:/hypercore/alter_table/
+[compression_continuous-aggregate]: /api/:currentVersion:/hypercore/alter_materialized_view/
+[convert_to_rowstore]: /api/:currentVersion:/hypercore/convert_to_rowstore/
+[convert_to_columnstore]: /api/:currentVersion:/hypercore/convert_to_columnstore/
+[informational-views]: /api/:currentVersion:/informational-views/jobs/
+[add_columnstore_policy]: /api/:currentVersion:/hypercore/add_columnstore_policy/
+[hypercore_workflow]: /api/:currentVersion:/hypercore/#hypercore-workflow
+[alter_job]: /api/:currentVersion:/actions/alter_job/
+[remove_columnstore_policy]: /api/:currentVersion:/hypercore/remove_columnstore_policy/
+[in-console-editors]: /getting-started/:currentVersion:/run-queries-from-console/
+[services-portal]: https://console.cloud.timescale.com/dashboard/services
+[connect-using-psql]: /use-timescale/:currentVersion:/integrations/query-admin/psql#connect-to-your-service
+[insert]: /use-timescale/:currentVersion:/write-data/insert/
+[hypercore]: /use-timescale/:currentVersion:/hypercore/
diff --git a/use-timescale/alerting.md b/use-timescale/alerting.md
index 837dd69511..dafb4a11c2 100644
--- a/use-timescale/alerting.md
+++ b/use-timescale/alerting.md
@@ -7,6 +7,8 @@ keywords: [alert, integration, Grafana, Datadog, Nagios, Zabbix]
# Alerting
+Early issue detecting and prevention, ensuring high availability, and performance optimization are only a few of the reasons why alerting plays a major role for modern applications, databases, and services.
+
There are a variety of different alerting solutions you can use in conjunction
with Timescale that are part of the PostgreSQL ecosystem. Regardless of
whether you are creating custom alerts embedded in your applications, or using
@@ -15,7 +17,7 @@ are a wide selection of tools available.
## Grafana
-Grafana is a great way to visualize and explore time-series data and has a
+Grafana is a great way to visualize your analytical queries, and it has a
first-class integration with Timescale. Beyond data visualization, Grafana
also provides alerting functionality to keep you notified of anomalies.
diff --git a/use-timescale/continuous-aggregates/hierarchical-continuous-aggregates.md b/use-timescale/continuous-aggregates/hierarchical-continuous-aggregates.md
index 0967936c11..706ee93b24 100644
--- a/use-timescale/continuous-aggregates/hierarchical-continuous-aggregates.md
+++ b/use-timescale/continuous-aggregates/hierarchical-continuous-aggregates.md
@@ -6,9 +6,9 @@ keywords: [continuous aggregates, hierarchical, create]
# Hierarchical continuous aggregates
-You can create continuous aggregates on top of other continuous aggregates. This
-allows you to summarize data at different levels of granularity. For example,
-you might have an hourly continuous aggregate that summarizes minute-by-minute
+The more data you have, the more likely you are to run a more sophisticated analysis on it. When a simple one-level aggregation is not enough, $CLOUD_LONG lets you create continuous aggregates on top of other continuous aggregates. This way, you summarize data at different levels of granularity, while still saving resources with precomputing.
+
+For example, you might have an hourly continuous aggregate that summarizes minute-by-minute
data. To get a daily summary, you can create a new continuous aggregate on top
of your hourly aggregate. This is more efficient than creating the daily
aggregate on top of the original hypertable, because you can reuse the
diff --git a/use-timescale/continuous-aggregates/index.md b/use-timescale/continuous-aggregates/index.md
index 84f701c6dd..902cf0187e 100644
--- a/use-timescale/continuous-aggregates/index.md
+++ b/use-timescale/continuous-aggregates/index.md
@@ -7,22 +7,20 @@ keywords: [continuous aggregates]
# Continuous aggregates
-Continuous aggregates are designed to make queries on very large datasets run
-faster. Timescale continuous aggregates use
-PostgreSQL [materialized views][postgres-materialized-views] to continuously and
-incrementally refresh a query in the background, so that when you run the query,
-only the data that has changed needs to be computed, not the entire dataset.
+From real-time dashboards to performance monitoring and historical trend analysis, data aggregation is a must-have for any sort of analytical application. To address this need, $CLOUD_LONG continuous aggregates precompute and store aggregate data for you. Using PostgreSQL [materialized views][postgres-materialized-views], continuous aggregates incrementally refresh the aggregation query in the background, so that when you do run it, only the data that has changed needs to be computed, not the entire dataset. This means you always have the latest aggregate data at your fingertips - and spend as little resources on it, as possible.
+
+In this section you:
* [Learn about continuous aggregates][about-caggs] to understand how it works
before you begin using it.
* [Create a continuous aggregate][cagg-create] and query it.
-* [Create a continuous aggregate on top of another continuous aggregate][cagg-on-cagg]
+* [Create a continuous aggregate on top of another continuous aggregate][cagg-on-cagg].
* [Add refresh policies][cagg-autorefresh] to an existing continuous aggregate.
* [Manage time][cagg-time] in your continuous aggregates.
* [Drop data][cagg-drop] from your continuous aggregates.
* [Manage materialized hypertables][cagg-mat-hypertables].
* [Use real-time aggregates][cagg-realtime].
-* [Compression with continuous aggregates][cagg-compression].
+* [Use compression with continuous aggregates][cagg-compression].
* [Migrate your continuous aggregates][cagg-migrate] from old to new format.
Continuous aggregates created in Timescale 2.7 and later are in the new
format, unless explicitly created in the old format.
diff --git a/use-timescale/continuous-aggregates/real-time-aggregates.md b/use-timescale/continuous-aggregates/real-time-aggregates.md
index cd861e20f5..4a7863b80b 100644
--- a/use-timescale/continuous-aggregates/real-time-aggregates.md
+++ b/use-timescale/continuous-aggregates/real-time-aggregates.md
@@ -7,35 +7,36 @@ keywords: [continuous aggregates, real-time aggregates]
import CaggsRealTimeHistoricalDataRefreshes from 'versionContent/_partials/_caggs-real-time-historical-data-refreshes.mdx';
-# Real time aggregates
+# Real-time aggregates
-Continuous aggregates do not include the most recent data chunk from the
-underlying hypertable. Real time aggregates use the aggregated data and add the
-most recent raw data to it to provide accurate and up to date results, without
-needing to aggregate data as it is being written. In Timescale versions 1.7 to 2.12,
-real time aggregates are enabled by default; when you create a continuous
+Rapidly growing data means you need more control over what to aggregate and how to aggregate it. With this in mind, $CLOUD_LONG equips you with tools for more fine-tuned data analysis.
+
+By default, continuous aggregates do not include the most recent data chunk from the
+underlying hypertable. Real-time aggregates, however, use the aggregated data **and** add the
+most recent raw data to it. This provides accurate and up-to-date results, without
+needing to aggregate data as it is being written.
+
+In Timescale 2.13 and later real-time aggregates are *DISABLED* by default. In Timescale versions 1.7 to 2.12, real-time aggregates are enabled by default; when you create a continuous
aggregate view, queries to that view include the most recent data, even if
-it has not yet been aggregated. In Timescale 2.13 and later real time aggregates are *DISABLED* by default.
+it has not yet been aggregated.
-For more detail on the comparison between continuous and real time aggregates,
+For more detail on the comparison between continuous and real-time aggregates,
see our [real time aggregate blog post][blog-rtaggs].
-## Use real time aggregates
+## Use real-time aggregates
-You can enable and disable real time aggregation by setting the
+You can enable and disable real-time aggregation by setting the
`materialized_only` parameter when you create or alter the view.
-### Using real time aggregation
-
-1. For an existing table, at the `psql` prompt, disable real time aggregation:
+1. For an existing table, at the `psql` prompt, disable real-time aggregation:
```sql
ALTER MATERIALIZED VIEW table_name set (timescaledb.materialized_only = true);
```
-1. Re-enable real time aggregation:
+1. Re-enable real-time aggregation:
```sql
ALTER MATERIALIZED VIEW table_name set (timescaledb.materialized_only = false);
diff --git a/use-timescale/data-retention/about-data-retention.md b/use-timescale/data-retention/about-data-retention.md
index 331e4ccaeb..ee879d975b 100644
--- a/use-timescale/data-retention/about-data-retention.md
+++ b/use-timescale/data-retention/about-data-retention.md
@@ -9,15 +9,12 @@ import UsageBasedStorage from "versionContent/_partials/_usage-based-storage-int
# About data retention
-In time-series applications, data often becomes less useful as it gets older. If
-you don't need your historical data, you can delete it once it reaches a certain
-age. Timescale lets you set up
-[automatic data retention policies][retention-policy] to discard old data. You
-can also fine-tune data retention by [manually dropping chunks][manual-drop].
-
-Often, you want to keep summaries of your historical data, but you don't need
-the raw data. You can downsample your older data by
-[combining data retention with continuous aggregates][retention-with-caggs].
+In modern applications, data grows exponentially. As data gets older, it often becomes less useful in day-to-day operations.
+However, you still need it for analysis. Timescale elegantly solves this problem with
+[automated data retention policies][retention-policy].
+
+Data retention policies delete raw old data for you on a schedule that you define.
+By [combining retention policies with continuous aggregates][retention-with-caggs], you can downsample your data and keep useful summaries of it instead. This lets you analyze historical data - while also saving on storage.
diff --git a/use-timescale/data-tiering/enabling-data-tiering.md b/use-timescale/data-tiering/enabling-data-tiering.md
index 4ae589a219..fb7f56ce5a 100644
--- a/use-timescale/data-tiering/enabling-data-tiering.md
+++ b/use-timescale/data-tiering/enabling-data-tiering.md
@@ -34,14 +34,14 @@ You enable tiered storage from the `Overview` tab in Console.
When tiered storage is enabled, you see the amount of data in the tiered object storage.
-
-
- Data tiering is available in [Scale and Enterprise][pricing-plans] pricing plans only.
-
-
-
+
+
+Data tiering is available in [Scale and Enterprise][pricing-plans] pricing plans only.
+
+
+
## Automate tiering with policies
A tiering policy automatically moves any chunks that only contain data
diff --git a/use-timescale/ha-replicas/high-availability.md b/use-timescale/ha-replicas/high-availability.md
index bfb3c56766..3834fe5749 100644
--- a/use-timescale/ha-replicas/high-availability.md
+++ b/use-timescale/ha-replicas/high-availability.md
@@ -9,6 +9,8 @@ cloud_ui:
- [services, :serviceId, operations, replication]
---
+import HASetup from 'versionContent/_partials/_high-availability-setup.mdx';
+
# Manage high availability
@@ -71,26 +73,12 @@ The `High` and `Highest` HA strategies are available with the [Scale and the Ent
To enable HA for a Timescale Cloud Service:
-
-
-1. In [Timescale Console][cloud-login], select the service to enable replication for.
-1. Click `Operations`, then select `High availability`.
-1. Choose your replication strategy, then click `Change configuration`.
-  -
-1. In `Change high availability configuration`, click `Change config`.
+
To change your HA replica strategy, click `Change configuration`, choose a strategy and click `Change configuration`.
To download the connection information for the HA replica, either click the link next to the replica
`Active configuration`, or find the information in the `Overview` tab for this service.
-
-
-
## Test failover for your HA replicas
To test the failover mechanism, you can trigger a switchover. A switchover is a
diff --git a/use-timescale/hyperfunctions/about-hyperfunctions.md b/use-timescale/hyperfunctions/about-hyperfunctions.md
index 4e27f5d3e3..248e2a7dc2 100644
--- a/use-timescale/hyperfunctions/about-hyperfunctions.md
+++ b/use-timescale/hyperfunctions/about-hyperfunctions.md
@@ -11,25 +11,18 @@ import ExperimentalUpgrade from "versionContent/_partials/_experimental-schema-u
# About Timescale hyperfunctions
-Timescale hyperfunctions are a specialized set of functions that allow you to
-analyze time-series data. You can use hyperfunctions to analyze anything you
-have stored as time-series data, including IoT devices, IT systems, marketing
-analytics, user behavior, financial metrics, and cryptocurrency.
+Timescale hyperfunctions are a specialized set of functions that power real-time analytics on time series and events.
+IoT devices, IT systems, marketing analytics, user behavior, financial metrics, cryptocurrency - these are only a few examples of domains where
+hyperfunctions can make a huge difference. Hyperfunctions provide you with meaningful, actionable insights in real time.
-Hyperfunctions allow you to perform critical time-series queries quickly,
-analyze time-series data, and extract meaningful information. They aim to
-identify, build, and combine all of the functionality SQL needs to perform
-time-series analysis into a single extension.
+$CLOUD_LONG includes all hyperfunctions by default, while self-hosted $TIMESCALE_DB includes a subset of them. For
+additional hyperfunctions, install the [Timescale Toolkit][install-toolkit] PostgreSQL extension.
-Some hyperfunctions are included in the default TimescaleDB product. For
-additional hyperfunctions, you need to install the
-[Timescale Toolkit][install-toolkit] PostgreSQL extension.
-
-## Hyperfunctions available with TimescaleDB and Timescale Toolkit
+## Available hyperfunctions
Here is a list of all the hyperfunctions provided by Timescale. Hyperfunctions
-marked 'Toolkit' require an installation of Timescale Toolkit. Hyperfunctions
-marked 'experimental' are still under development.
+with a tick in the `Toolkit` column require an installation of Timescale Toolkit for self-hosted deployments. Hyperfunctions
+with a tick in the `Experimental` column are still under development.
diff --git a/use-timescale/hyperfunctions/heartbeat-agg.md b/use-timescale/hyperfunctions/heartbeat-agg.md
index 6a51f8263a..94b71b837d 100644
--- a/use-timescale/hyperfunctions/heartbeat-agg.md
+++ b/use-timescale/hyperfunctions/heartbeat-agg.md
@@ -8,10 +8,11 @@ keywords: [hyperfunctions, Toolkit, heartbeat, liveness]
Given a series of timestamped health checks, it can be tricky to determine the
overall health of a system over a given interval. PostgresQL provides window
-functions which can be used to get a sense of where unhealthy gaps are, but can
-be somewhat awkward to use efficiently. The heartbeat aggregate is part of the
-Timescale Toolkit, and can be used to solve this problem in a simpler, more
-accessible manner.
+functions which you use to get a sense of where unhealthy gaps are, but can
+be somewhat awkward to use efficiently.
+
+This is one of the many cases where hyperfunctions provide an efficient, simple solution for
+a frequently occurring problem. Heartbeat aggregation helps analyze event-based time-series data with intermittent or irregular signals.
This example uses the [SustData public dataset][sustdata]. This dataset tracks
the power usage of a small number of apartments and houses over four different
@@ -19,7 +20,7 @@ deployment intervals. The data is collected in one minute samples from each
unit.
When you have loaded the data into hypertables, you can create a materialized
-view containing weekly heartbeat aggregates for each of the units.
+view containing weekly heartbeat aggregates for each of the units:
```sql
CREATE MATERIALIZED VIEW weekly_heartbeat AS
@@ -69,7 +70,7 @@ SELECT live_ranges(rollup(heartbeat_agg)) FROM weekly_heartbeat WHERE unit = 17;
("2012-03-25 03:00:51+00","2012-04-11 00:01:00+00")
```
-You can do also do more elaborate queries, like looking for the 5 units with the
+You can construct more elaborate queries. For example, to return the 5 units with the
lowest uptime during the third deployment:
```sql
@@ -90,7 +91,7 @@ ORDER BY uptime LIMIT 5;
30 | 222 days 22:05:00
```
-You can also combine aggregates from different units to get the combined
+Combine aggregates from different units to get the combined
coverage. This example queries the interval where any part of a deployment was
active:
@@ -115,11 +116,12 @@ FROM weekly_heartbeat group by deploy order by deploy;
4 | ("2014-03-30 03:00:01+00","2014-04-25 00:01:00+00")
```
-You can use this data to make some observations. First, it looks like the second
-deployment had a lot more problems than the other ones. Second, it looks like
-there were some readings from February 2013 that were incorrectly categorized as
-a second deployment. And finally, it looks like the timestamps are given in a
-local time without time zone, resulting in some missing hours around springtime
+Then use this data to make observations and draw conclusions:
+
+- The second deployment had a lot more problems than the other ones.
+- There were some readings from February 2013 that were incorrectly categorized as
+a second deployment.
+- The timestamps are given in a local time without time zone, resulting in some missing hours around springtime
daylight savings time changes.
For more information about heartbeat aggregation API calls, see the
diff --git a/use-timescale/hyperfunctions/index.md b/use-timescale/hyperfunctions/index.md
index 41168901f3..1887625014 100644
--- a/use-timescale/hyperfunctions/index.md
+++ b/use-timescale/hyperfunctions/index.md
@@ -7,12 +7,10 @@ keywords: [hyperfunctions, Toolkit, analytics]
# Hyperfunctions
-Hyperfunctions allow you to perform critical time-series queries quickly,
-analyze time-series data, and extract meaningful information.
+Timescale hyperfunctions are designed to efficiently process, aggregate, and analyze significant volumes of data while maintaining high performance.
+They let you run sophisticated analytical queries and get meaningful data in real time.
-Some hyperfunctions are included by default in Timescale. For
-additional hyperfunctions, you need to install the
-[Timescale Toolkit][install-toolkit] PostgreSQL extension.
+$CLOUD_LONG includes all hyperfunctions by default, while self-hosted $TIMESCALE_DB includes a subset of them. To include all hyperfunctions with $TIMESCALE_DB, install the [Timescale Toolkit][install-toolkit] PostgreSQL extension on your self-hosted PostgreSQL deployment.
For more information, read the [hyperfunctions blog post][hyperfunctions-blog].
@@ -21,7 +19,7 @@ For more information, read the [hyperfunctions blog post][hyperfunctions-blog].
* [Learn about hyperfunctions][about-hyperfunctions] to understand how they
work before using them.
* Install the [Toolkit extension][install-toolkit] to access more
- hyperfunctions.
+ hyperfunctions on self-hosted $TIMESCALE_DB.
## Browse hyperfunctions and Toolkit features by category
diff --git a/use-timescale/hypertables/about-hypertables.md b/use-timescale/hypertables/about-hypertables.md
index 1c77c0bac3..5ca8132a3c 100644
--- a/use-timescale/hypertables/about-hypertables.md
+++ b/use-timescale/hypertables/about-hypertables.md
@@ -17,10 +17,7 @@ Inheritance is not supported for hypertables and may lead to unexpected behavior
## Hypertable partitioning
-When you create and use a hypertable, it automatically partitions data by time,
-and optionally by space.
-
-Each hypertable is made up of child tables called chunks. Each chunk is assigned
+Each hypertable is partitioned into child tables called chunks. Each chunk is assigned
a range of time, and only contains data from that range. If the hypertable is
also partitioned by space, each chunk is also assigned a subset of the space
values.
@@ -36,7 +33,7 @@ it makes sense.
### Time partitioning
Each chunk of a hypertable only holds data from a specific time range. When you
-insert data from a time range that doesn't yet have a chunk, Timescale
+insert data from a time range that doesn't yet have a chunk, $CLOUD_LONG
automatically creates a chunk to store it.
By default, each chunk covers 7 days. You can change this to better suit your
@@ -50,7 +47,7 @@ alt="A normal table compared to a hypertable. The normal table holds data for 3
/>
-Timescale divides time into potential chunk ranges, based on the
+$CLOUD_LONG divides time into potential chunk ranges, based on the
`chunk_time_interval`. If data exists for a potential chunk range, that chunk is
created.
@@ -70,7 +67,7 @@ affect query planning time and compression.
Best practice is to set `chunk_time_interval` so that prior to processing, one chunk of data
takes up 25% of main memory, including the indexes from each active hypertable.
-For example, if your write approximately 2 GB of data per day to a database with 64 GB of
+For example, if you write approximately 2 GB of data per day to a database with 64 GB of
memory, set `chunk_time_interval` to 1 week. If you write approximately 10 GB of data per day
on the same machine, set the time interval to 1 day.
diff --git a/use-timescale/hypertables/improve-query-performance.md b/use-timescale/hypertables/improve-query-performance.md
index e6d1d8219b..be08f1c0ca 100644
--- a/use-timescale/hypertables/improve-query-performance.md
+++ b/use-timescale/hypertables/improve-query-performance.md
@@ -7,6 +7,7 @@ keywords: [hypertables, indexes, chunks]
# Improve query performance
+One of the key purposes of hypertables is to make your analytical queries run with the lowest latency possible - and they have been designed accordingly.
When you execute a query on a hypertable, you do not parse the whole table; you only access the chunks necessary
to satisfy the query. This works well when the `WHERE` clause of a query uses the column by which a hypertable is
partitioned. For example, in a hypertable where every day of the year is a separate chunk, a query for September 1
diff --git a/use-timescale/hypertables/index.md b/use-timescale/hypertables/index.md
index d179cb74df..101225c528 100644
--- a/use-timescale/hypertables/index.md
+++ b/use-timescale/hypertables/index.md
@@ -7,10 +7,8 @@ keywords: [hypertables]
# Hypertables
-Hypertables are PostgreSQL tables with special features that make it easy to
-handle time-series data. Anything you can do with regular PostgreSQL tables, you
-can do with hypertables. In addition, you get the benefits of improved
-performance and user experience for time-series data.
+Hypertables are PostgreSQL tables designed to simplify and accelerate data analysis. Anything you can do with regular PostgreSQL tables, you
+can do with hypertables - but much faster and more conveniently. In this section, you:
* [Learn about hypertables][about-hypertables]
* [Create a hypertable][create-hypertables]
diff --git a/use-timescale/integrations/apache-airflow.md b/use-timescale/integrations/apache-airflow.md
index 17e8071750..72e92133ea 100644
--- a/use-timescale/integrations/apache-airflow.md
+++ b/use-timescale/integrations/apache-airflow.md
@@ -98,7 +98,7 @@ To exchange data between Airflow and your $SERVICE_LONG:
This could be any query. This example inserts data into the table
you create in:
- https://docs.timescale.com/getting-started/latest/tables-hypertables/#create-regular-postgresql-tables-for-relational-data
+ https://docs.timescale.com/getting-started/latest/try-key-features-timescale-products/#optimize-time-series-data-in-hypertables
"""
cursor.execute("INSERT INTO company (symbol, name) VALUES (%s, %s)",
('new_company_symbol', 'New Company Name'))
@@ -138,7 +138,7 @@ To exchange data between Airflow and your $SERVICE_LONG:
You have successfully integrated Apache Airflow with $CLOUD_LONG and created a data pipeline.
-[create-a-table-in-timescale]: /getting-started/:currentVersion:/tables-hypertables/#create-regular-postgresql-tables-for-relational-data
+[create-a-table-in-timescale]: /getting-started/:currentVersion:/try-key-features-timescale-products/#optimize-time-series-data-in-hypertables
[install-apache-airflow]: https://airflow.apache.org/docs/apache-airflow/stable/start.html
[install-python-pip]: https://docs.python.org/3/using/index.html
[console]: https://console.cloud.timescale.com/
diff --git a/use-timescale/integrations/datadog.md b/use-timescale/integrations/datadog.md
index df76c78268..3dc934a47c 100644
--- a/use-timescale/integrations/datadog.md
+++ b/use-timescale/integrations/datadog.md
@@ -39,4 +39,4 @@ tool. You create an exporter on the [project level][projects], in the same AWS r
[datadog-signup]: https://www.datadoghq.com/
[projects]: /use-timescale/:currentVersion:/members/
[datadog-api-key]: https://docs.datadoghq.com/account_management/api-app-keys/#add-an-api-key-or-client-token
-[pricing-plan-features]: /about/:currentVersion:/pricing-and-account-management/#features-included-in-each-plan
\ No newline at end of file
+[pricing-plan-features]: /about/:currentVersion:/pricing-and-account-management/#features-included-in-each-plan
diff --git a/use-timescale/integrations/grafana.md b/use-timescale/integrations/grafana.md
index a42b3556a4..102f6fbe70 100644
--- a/use-timescale/integrations/grafana.md
+++ b/use-timescale/integrations/grafana.md
@@ -4,7 +4,7 @@ excerpt: Grafana enables you to query, visualize, alert on, and explore your met
products: [cloud]
keywords: [Grafana, visualizations, analytics, monitoring]
---
-
+import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
import GrafanaConnect from "versionContent/_partials/_grafana-connect.mdx";
# Integrate Grafana and Timescale Cloud
@@ -13,6 +13,12 @@ import GrafanaConnect from "versionContent/_partials/_grafana-connect.mdx";
This page shows you how to integrate Grafana with a $SERVICE_LONG, create a dashboard and panel, then visualize geospatial data.
+## Prerequisites
+
+
+
+* Install [self-managed Grafana][grafana-self-managed] or sign up for [Grafana Cloud][grafana-cloud].
+
## Create a Grafana dashboard and panel
@@ -177,4 +183,5 @@ tutorial as a starting point.
[nyc-taxi]: /tutorials/:currentVersion:/nyc-taxi-cab
[grafana-website]: https://www.grafana.com
[time-buckets]: /use-timescale/:currentVersion:/time-buckets/
-
+[grafana-self-managed]: https://grafana.com/get/?tab=self-managed
+[grafana-cloud]: https://grafana.com/get/
diff --git a/use-timescale/time-buckets/about-time-buckets.md b/use-timescale/time-buckets/about-time-buckets.md
index c2ff30d373..0dab19f29e 100644
--- a/use-timescale/time-buckets/about-time-buckets.md
+++ b/use-timescale/time-buckets/about-time-buckets.md
@@ -7,19 +7,17 @@ keywords: [time buckets]
# About time buckets
-The [`time_bucket`][time_bucket] function allows you to aggregate data in a
-[hypertable][create-hypertable] into buckets of time. For example: 5 minutes, 1 hour, or 3 days.
+Time bucketing is essential for real-time analytics. The [`time_bucket`][time_bucket] function enables you to aggregate data in a [hypertable][create-hypertable] into buckets of time. For example, 5 minutes, 1 hour, or 3 days.
It's similar to PostgreSQL's [`date_bin`][date_bin] function, but it gives you more
-flexibility in bucket size and start time.
+flexibility in the bucket size and start time.
-Time bucketing is essential to working with time-series data. You can use it to
-roll up data for analysis or downsampling. For example, you can calculate
+You can use it to roll up data for analysis or downsampling. For example, you can calculate
5-minute averages for a sensor reading over the last day. You can perform these
rollups as needed, or pre-calculate them in [continuous aggregates][caggs].
This section explains how time bucketing works. For examples of the
`time_bucket` function, see the section on
-[using time buckets][use-time-buckets].
+[Aggregate time-series data with `time_bucket`][use-time-buckets].
## How time bucketing works
diff --git a/use-timescale/time-buckets/index.md b/use-timescale/time-buckets/index.md
index d766900317..d728b6d522 100644
--- a/use-timescale/time-buckets/index.md
+++ b/use-timescale/time-buckets/index.md
@@ -10,7 +10,7 @@ keywords: [time buckets]
Time buckets enable you to aggregate data in [hypertables][create-hypertable] by time interval. For example, you can
group data into 5-minute, 1-hour, and 3-day buckets to calculate summary values.
-* [Learn how time buckets work][about-time-buckets] in Timescale
+* [Learn how time buckets work][about-time-buckets] in $CLOUD_LONG
* [Use time buckets][use-time-buckets] to aggregate data
[about-time-buckets]: /use-timescale/:currentVersion:/time-buckets/about-time-buckets/
diff --git a/use-timescale/write-data/about-writing-data.md b/use-timescale/write-data/about-writing-data.md
index 1e40441c0b..1d28585a5d 100644
--- a/use-timescale/write-data/about-writing-data.md
+++ b/use-timescale/write-data/about-writing-data.md
@@ -12,7 +12,7 @@ Timescale supports writing data in the same way as PostgreSQL, using `INSERT`,
`UPDATE`, `INSERT ... ON CONFLICT`, and `DELETE`.
-Because Timescale is a time-series database, hypertables are optimized for
+$CLOUD_LONG is optimized for running real-time analytics workloads on time-series data. For this reason, hypertables are optimized for
inserts to the most recent time intervals. Inserting data with recent time
values gives
[excellent performance](https://www.timescale.com/blog/timescaledb-vs-6a696248104e/).
-
-1. In `Change high availability configuration`, click `Change config`.
+
To change your HA replica strategy, click `Change configuration`, choose a strategy and click `Change configuration`.
To download the connection information for the HA replica, either click the link next to the replica
`Active configuration`, or find the information in the `Overview` tab for this service.
-
-
-
## Test failover for your HA replicas
To test the failover mechanism, you can trigger a switchover. A switchover is a
diff --git a/use-timescale/hyperfunctions/about-hyperfunctions.md b/use-timescale/hyperfunctions/about-hyperfunctions.md
index 4e27f5d3e3..248e2a7dc2 100644
--- a/use-timescale/hyperfunctions/about-hyperfunctions.md
+++ b/use-timescale/hyperfunctions/about-hyperfunctions.md
@@ -11,25 +11,18 @@ import ExperimentalUpgrade from "versionContent/_partials/_experimental-schema-u
# About Timescale hyperfunctions
-Timescale hyperfunctions are a specialized set of functions that allow you to
-analyze time-series data. You can use hyperfunctions to analyze anything you
-have stored as time-series data, including IoT devices, IT systems, marketing
-analytics, user behavior, financial metrics, and cryptocurrency.
+Timescale hyperfunctions are a specialized set of functions that power real-time analytics on time series and events.
+IoT devices, IT systems, marketing analytics, user behavior, financial metrics, cryptocurrency - these are only a few examples of domains where
+hyperfunctions can make a huge difference. Hyperfunctions provide you with meaningful, actionable insights in real time.
-Hyperfunctions allow you to perform critical time-series queries quickly,
-analyze time-series data, and extract meaningful information. They aim to
-identify, build, and combine all of the functionality SQL needs to perform
-time-series analysis into a single extension.
+$CLOUD_LONG includes all hyperfunctions by default, while self-hosted $TIMESCALE_DB includes a subset of them. For
+additional hyperfunctions, install the [Timescale Toolkit][install-toolkit] PostgreSQL extension.
-Some hyperfunctions are included in the default TimescaleDB product. For
-additional hyperfunctions, you need to install the
-[Timescale Toolkit][install-toolkit] PostgreSQL extension.
-
-## Hyperfunctions available with TimescaleDB and Timescale Toolkit
+## Available hyperfunctions
Here is a list of all the hyperfunctions provided by Timescale. Hyperfunctions
-marked 'Toolkit' require an installation of Timescale Toolkit. Hyperfunctions
-marked 'experimental' are still under development.
+with a tick in the `Toolkit` column require an installation of Timescale Toolkit for self-hosted deployments. Hyperfunctions
+with a tick in the `Experimental` column are still under development.
diff --git a/use-timescale/hyperfunctions/heartbeat-agg.md b/use-timescale/hyperfunctions/heartbeat-agg.md
index 6a51f8263a..94b71b837d 100644
--- a/use-timescale/hyperfunctions/heartbeat-agg.md
+++ b/use-timescale/hyperfunctions/heartbeat-agg.md
@@ -8,10 +8,11 @@ keywords: [hyperfunctions, Toolkit, heartbeat, liveness]
Given a series of timestamped health checks, it can be tricky to determine the
overall health of a system over a given interval. PostgresQL provides window
-functions which can be used to get a sense of where unhealthy gaps are, but can
-be somewhat awkward to use efficiently. The heartbeat aggregate is part of the
-Timescale Toolkit, and can be used to solve this problem in a simpler, more
-accessible manner.
+functions which you use to get a sense of where unhealthy gaps are, but can
+be somewhat awkward to use efficiently.
+
+This is one of the many cases where hyperfunctions provide an efficient, simple solution for
+a frequently occurring problem. Heartbeat aggregation helps analyze event-based time-series data with intermittent or irregular signals.
This example uses the [SustData public dataset][sustdata]. This dataset tracks
the power usage of a small number of apartments and houses over four different
@@ -19,7 +20,7 @@ deployment intervals. The data is collected in one minute samples from each
unit.
When you have loaded the data into hypertables, you can create a materialized
-view containing weekly heartbeat aggregates for each of the units.
+view containing weekly heartbeat aggregates for each of the units:
```sql
CREATE MATERIALIZED VIEW weekly_heartbeat AS
@@ -69,7 +70,7 @@ SELECT live_ranges(rollup(heartbeat_agg)) FROM weekly_heartbeat WHERE unit = 17;
("2012-03-25 03:00:51+00","2012-04-11 00:01:00+00")
```
-You can do also do more elaborate queries, like looking for the 5 units with the
+You can construct more elaborate queries. For example, to return the 5 units with the
lowest uptime during the third deployment:
```sql
@@ -90,7 +91,7 @@ ORDER BY uptime LIMIT 5;
30 | 222 days 22:05:00
```
-You can also combine aggregates from different units to get the combined
+Combine aggregates from different units to get the combined
coverage. This example queries the interval where any part of a deployment was
active:
@@ -115,11 +116,12 @@ FROM weekly_heartbeat group by deploy order by deploy;
4 | ("2014-03-30 03:00:01+00","2014-04-25 00:01:00+00")
```
-You can use this data to make some observations. First, it looks like the second
-deployment had a lot more problems than the other ones. Second, it looks like
-there were some readings from February 2013 that were incorrectly categorized as
-a second deployment. And finally, it looks like the timestamps are given in a
-local time without time zone, resulting in some missing hours around springtime
+Then use this data to make observations and draw conclusions:
+
+- The second deployment had a lot more problems than the other ones.
+- There were some readings from February 2013 that were incorrectly categorized as
+a second deployment.
+- The timestamps are given in a local time without time zone, resulting in some missing hours around springtime
daylight savings time changes.
For more information about heartbeat aggregation API calls, see the
diff --git a/use-timescale/hyperfunctions/index.md b/use-timescale/hyperfunctions/index.md
index 41168901f3..1887625014 100644
--- a/use-timescale/hyperfunctions/index.md
+++ b/use-timescale/hyperfunctions/index.md
@@ -7,12 +7,10 @@ keywords: [hyperfunctions, Toolkit, analytics]
# Hyperfunctions
-Hyperfunctions allow you to perform critical time-series queries quickly,
-analyze time-series data, and extract meaningful information.
+Timescale hyperfunctions are designed to efficiently process, aggregate, and analyze significant volumes of data while maintaining high performance.
+They let you run sophisticated analytical queries and get meaningful data in real time.
-Some hyperfunctions are included by default in Timescale. For
-additional hyperfunctions, you need to install the
-[Timescale Toolkit][install-toolkit] PostgreSQL extension.
+$CLOUD_LONG includes all hyperfunctions by default, while self-hosted $TIMESCALE_DB includes a subset of them. To include all hyperfunctions with $TIMESCALE_DB, install the [Timescale Toolkit][install-toolkit] PostgreSQL extension on your self-hosted PostgreSQL deployment.
For more information, read the [hyperfunctions blog post][hyperfunctions-blog].
@@ -21,7 +19,7 @@ For more information, read the [hyperfunctions blog post][hyperfunctions-blog].
* [Learn about hyperfunctions][about-hyperfunctions] to understand how they
work before using them.
* Install the [Toolkit extension][install-toolkit] to access more
- hyperfunctions.
+ hyperfunctions on self-hosted $TIMESCALE_DB.
## Browse hyperfunctions and Toolkit features by category
diff --git a/use-timescale/hypertables/about-hypertables.md b/use-timescale/hypertables/about-hypertables.md
index 1c77c0bac3..5ca8132a3c 100644
--- a/use-timescale/hypertables/about-hypertables.md
+++ b/use-timescale/hypertables/about-hypertables.md
@@ -17,10 +17,7 @@ Inheritance is not supported for hypertables and may lead to unexpected behavior
## Hypertable partitioning
-When you create and use a hypertable, it automatically partitions data by time,
-and optionally by space.
-
-Each hypertable is made up of child tables called chunks. Each chunk is assigned
+Each hypertable is partitioned into child tables called chunks. Each chunk is assigned
a range of time, and only contains data from that range. If the hypertable is
also partitioned by space, each chunk is also assigned a subset of the space
values.
@@ -36,7 +33,7 @@ it makes sense.
### Time partitioning
Each chunk of a hypertable only holds data from a specific time range. When you
-insert data from a time range that doesn't yet have a chunk, Timescale
+insert data from a time range that doesn't yet have a chunk, $CLOUD_LONG
automatically creates a chunk to store it.
By default, each chunk covers 7 days. You can change this to better suit your
@@ -50,7 +47,7 @@ alt="A normal table compared to a hypertable. The normal table holds data for 3
/>
-Timescale divides time into potential chunk ranges, based on the
+$CLOUD_LONG divides time into potential chunk ranges, based on the
`chunk_time_interval`. If data exists for a potential chunk range, that chunk is
created.
@@ -70,7 +67,7 @@ affect query planning time and compression.
Best practice is to set `chunk_time_interval` so that prior to processing, one chunk of data
takes up 25% of main memory, including the indexes from each active hypertable.
-For example, if your write approximately 2 GB of data per day to a database with 64 GB of
+For example, if you write approximately 2 GB of data per day to a database with 64 GB of
memory, set `chunk_time_interval` to 1 week. If you write approximately 10 GB of data per day
on the same machine, set the time interval to 1 day.
diff --git a/use-timescale/hypertables/improve-query-performance.md b/use-timescale/hypertables/improve-query-performance.md
index e6d1d8219b..be08f1c0ca 100644
--- a/use-timescale/hypertables/improve-query-performance.md
+++ b/use-timescale/hypertables/improve-query-performance.md
@@ -7,6 +7,7 @@ keywords: [hypertables, indexes, chunks]
# Improve query performance
+One of the key purposes of hypertables is to make your analytical queries run with the lowest latency possible - and they have been designed accordingly.
When you execute a query on a hypertable, you do not parse the whole table; you only access the chunks necessary
to satisfy the query. This works well when the `WHERE` clause of a query uses the column by which a hypertable is
partitioned. For example, in a hypertable where every day of the year is a separate chunk, a query for September 1
diff --git a/use-timescale/hypertables/index.md b/use-timescale/hypertables/index.md
index d179cb74df..101225c528 100644
--- a/use-timescale/hypertables/index.md
+++ b/use-timescale/hypertables/index.md
@@ -7,10 +7,8 @@ keywords: [hypertables]
# Hypertables
-Hypertables are PostgreSQL tables with special features that make it easy to
-handle time-series data. Anything you can do with regular PostgreSQL tables, you
-can do with hypertables. In addition, you get the benefits of improved
-performance and user experience for time-series data.
+Hypertables are PostgreSQL tables designed to simplify and accelerate data analysis. Anything you can do with regular PostgreSQL tables, you
+can do with hypertables - but much faster and more conveniently. In this section, you:
* [Learn about hypertables][about-hypertables]
* [Create a hypertable][create-hypertables]
diff --git a/use-timescale/integrations/apache-airflow.md b/use-timescale/integrations/apache-airflow.md
index 17e8071750..72e92133ea 100644
--- a/use-timescale/integrations/apache-airflow.md
+++ b/use-timescale/integrations/apache-airflow.md
@@ -98,7 +98,7 @@ To exchange data between Airflow and your $SERVICE_LONG:
This could be any query. This example inserts data into the table
you create in:
- https://docs.timescale.com/getting-started/latest/tables-hypertables/#create-regular-postgresql-tables-for-relational-data
+ https://docs.timescale.com/getting-started/latest/try-key-features-timescale-products/#optimize-time-series-data-in-hypertables
"""
cursor.execute("INSERT INTO company (symbol, name) VALUES (%s, %s)",
('new_company_symbol', 'New Company Name'))
@@ -138,7 +138,7 @@ To exchange data between Airflow and your $SERVICE_LONG:
You have successfully integrated Apache Airflow with $CLOUD_LONG and created a data pipeline.
-[create-a-table-in-timescale]: /getting-started/:currentVersion:/tables-hypertables/#create-regular-postgresql-tables-for-relational-data
+[create-a-table-in-timescale]: /getting-started/:currentVersion:/try-key-features-timescale-products/#optimize-time-series-data-in-hypertables
[install-apache-airflow]: https://airflow.apache.org/docs/apache-airflow/stable/start.html
[install-python-pip]: https://docs.python.org/3/using/index.html
[console]: https://console.cloud.timescale.com/
diff --git a/use-timescale/integrations/datadog.md b/use-timescale/integrations/datadog.md
index df76c78268..3dc934a47c 100644
--- a/use-timescale/integrations/datadog.md
+++ b/use-timescale/integrations/datadog.md
@@ -39,4 +39,4 @@ tool. You create an exporter on the [project level][projects], in the same AWS r
[datadog-signup]: https://www.datadoghq.com/
[projects]: /use-timescale/:currentVersion:/members/
[datadog-api-key]: https://docs.datadoghq.com/account_management/api-app-keys/#add-an-api-key-or-client-token
-[pricing-plan-features]: /about/:currentVersion:/pricing-and-account-management/#features-included-in-each-plan
\ No newline at end of file
+[pricing-plan-features]: /about/:currentVersion:/pricing-and-account-management/#features-included-in-each-plan
diff --git a/use-timescale/integrations/grafana.md b/use-timescale/integrations/grafana.md
index a42b3556a4..102f6fbe70 100644
--- a/use-timescale/integrations/grafana.md
+++ b/use-timescale/integrations/grafana.md
@@ -4,7 +4,7 @@ excerpt: Grafana enables you to query, visualize, alert on, and explore your met
products: [cloud]
keywords: [Grafana, visualizations, analytics, monitoring]
---
-
+import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
import GrafanaConnect from "versionContent/_partials/_grafana-connect.mdx";
# Integrate Grafana and Timescale Cloud
@@ -13,6 +13,12 @@ import GrafanaConnect from "versionContent/_partials/_grafana-connect.mdx";
This page shows you how to integrate Grafana with a $SERVICE_LONG, create a dashboard and panel, then visualize geospatial data.
+## Prerequisites
+
+
+
+* Install [self-managed Grafana][grafana-self-managed] or sign up for [Grafana Cloud][grafana-cloud].
+
## Create a Grafana dashboard and panel
@@ -177,4 +183,5 @@ tutorial as a starting point.
[nyc-taxi]: /tutorials/:currentVersion:/nyc-taxi-cab
[grafana-website]: https://www.grafana.com
[time-buckets]: /use-timescale/:currentVersion:/time-buckets/
-
+[grafana-self-managed]: https://grafana.com/get/?tab=self-managed
+[grafana-cloud]: https://grafana.com/get/
diff --git a/use-timescale/time-buckets/about-time-buckets.md b/use-timescale/time-buckets/about-time-buckets.md
index c2ff30d373..0dab19f29e 100644
--- a/use-timescale/time-buckets/about-time-buckets.md
+++ b/use-timescale/time-buckets/about-time-buckets.md
@@ -7,19 +7,17 @@ keywords: [time buckets]
# About time buckets
-The [`time_bucket`][time_bucket] function allows you to aggregate data in a
-[hypertable][create-hypertable] into buckets of time. For example: 5 minutes, 1 hour, or 3 days.
+Time bucketing is essential for real-time analytics. The [`time_bucket`][time_bucket] function enables you to aggregate data in a [hypertable][create-hypertable] into buckets of time. For example, 5 minutes, 1 hour, or 3 days.
It's similar to PostgreSQL's [`date_bin`][date_bin] function, but it gives you more
-flexibility in bucket size and start time.
+flexibility in the bucket size and start time.
-Time bucketing is essential to working with time-series data. You can use it to
-roll up data for analysis or downsampling. For example, you can calculate
+You can use it to roll up data for analysis or downsampling. For example, you can calculate
5-minute averages for a sensor reading over the last day. You can perform these
rollups as needed, or pre-calculate them in [continuous aggregates][caggs].
This section explains how time bucketing works. For examples of the
`time_bucket` function, see the section on
-[using time buckets][use-time-buckets].
+[Aggregate time-series data with `time_bucket`][use-time-buckets].
## How time bucketing works
diff --git a/use-timescale/time-buckets/index.md b/use-timescale/time-buckets/index.md
index d766900317..d728b6d522 100644
--- a/use-timescale/time-buckets/index.md
+++ b/use-timescale/time-buckets/index.md
@@ -10,7 +10,7 @@ keywords: [time buckets]
Time buckets enable you to aggregate data in [hypertables][create-hypertable] by time interval. For example, you can
group data into 5-minute, 1-hour, and 3-day buckets to calculate summary values.
-* [Learn how time buckets work][about-time-buckets] in Timescale
+* [Learn how time buckets work][about-time-buckets] in $CLOUD_LONG
* [Use time buckets][use-time-buckets] to aggregate data
[about-time-buckets]: /use-timescale/:currentVersion:/time-buckets/about-time-buckets/
diff --git a/use-timescale/write-data/about-writing-data.md b/use-timescale/write-data/about-writing-data.md
index 1e40441c0b..1d28585a5d 100644
--- a/use-timescale/write-data/about-writing-data.md
+++ b/use-timescale/write-data/about-writing-data.md
@@ -12,7 +12,7 @@ Timescale supports writing data in the same way as PostgreSQL, using `INSERT`,
`UPDATE`, `INSERT ... ON CONFLICT`, and `DELETE`.
-Because Timescale is a time-series database, hypertables are optimized for
+$CLOUD_LONG is optimized for running real-time analytics workloads on time-series data. For this reason, hypertables are optimized for
inserts to the most recent time intervals. Inserting data with recent time
values gives
[excellent performance](https://www.timescale.com/blog/timescaledb-vs-6a696248104e/).