Add some more details to the snapshot #47359
Conversation
src/gc-heap-snapshot.cpp
Outdated
| { | ||
| size_t name_or_idx = g_snapshot->names.find_or_create_string_id("<native>"); | ||
|
|
||
| auto from_node_idx = record_node_to_gc_snapshot(from); | ||
| auto to_node_idx = record_pointer_to_gc_snapshot(to, bytes, "<malloc>"); | ||
| auto alloc_type = pooled ? "<pooled>" : "<malloc>"; |
There was a problem hiding this comment.
I don't think pooled is the right term. I think we have inline, malloc, foreign. And I think in the case of inline we should increase the size reported here?
There was a problem hiding this comment.
Pooled was the name of the flag in the jl_array_t struct. Why would it report the wrong size in this case?
There was a problem hiding this comment.
Ah we actually have 4 different classes.
- small arrays are inline allocated
- medium sized array -> pooled
- large array -> malloced
- foreign: Who knows.
Now I remember that when were looking together at some snapshots one some arrays contained a pointer to a data object.
There was a problem hiding this comment.
Foreign arrays are treated exactly like malloced arrays. I found that out while playing with mimalloc, that's why I needed an extra bit in the array because to make it work one can't assume the same allocator for the foreign arrays as the local ones. We currently ignore the inlined arrays in the snapshot. I will see if I can add them however.
There was a problem hiding this comment.
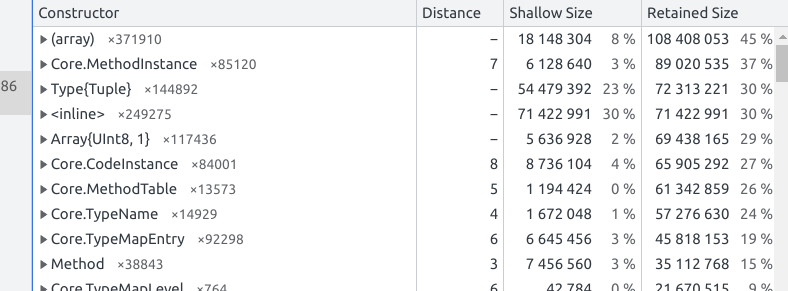
I think I found a couple megabytes sneaking around
There was a problem hiding this comment.
This actually made it a lot more useful because we can now see the size of the inferred code.
| else if (jl_is_datatype(a)) { | ||
| type_name = string("Type{") + string(jl_symbol_name_(((_jl_datatype_t*)a)->name->name)) + string("}"); | ||
| name = StringRef(type_name); | ||
| self_size = sizeof(jl_task_t); | ||
| } |
There was a problem hiding this comment.
What was the output for datatypes before this PR? Was it just DataType?
I think that this should be improved even further after #47503.
Thanks! :)
There was a problem hiding this comment.
Yes, before this PR it was DataType, with it we got what "kind" of DataType and with that one we should get the specific type.
This distinguishes malloced allocations from pool allocations in arrays. It also changes the printing of DataType to print the actual type. Same for module, where it gives the module name instead of Module