Add SSE2 version of Mean16x4 #1814
Conversation
Codecov Report
@@ Coverage Diff @@
## master #1814 +/- ##
==========================================
+ Coverage 87.13% 87.35% +0.22%
==========================================
Files 936 936
Lines 48128 48154 +26
Branches 6037 6038 +1
==========================================
+ Hits 41934 42063 +129
+ Misses 5190 5092 -98
+ Partials 1004 999 -5
Flags with carried forward coverage won't be shown. Click here to find out more.
Continue to review full report at Codecov.
|

| fixed (byte* inputPtr = input) | ||
| fixed (ushort* tmpPtr = tmp) |
There was a problem hiding this comment.
Same recommendations to avoid pinning. Alternatively you can pin YuvIn before the for (k = 0; k < 16; k += 4) loop, and pass pointers to the method.
| ref ushort outputRef = ref MemoryMarshal.GetReference(tmp); | ||
| Unsafe.As<ushort, Vector128<ushort>>(ref outputRef) = f0.AsUInt16(); | ||
|
|
||
| dc[0] = (uint)(tmp[1] + tmp[0]); |
There was a problem hiding this comment.
It looks to me like if you reverse these span assignments you'll cut out 9 of 12 bounds checks.
| dc[0] = (uint)(tmp[1] + tmp[0]); | ||
| dc[1] = (uint)(tmp[3] + tmp[2]); | ||
| dc[2] = (uint)(tmp[5] + tmp[4]); | ||
| dc[3] = (uint)(tmp[7] + tmp[6]); |
There was a problem hiding this comment.
Isn't this the same as _mm_hadd_epi16 aka. Ssse3.HorizontalAdd?
I'm afraid 12 span indexer bound checks have measureable impact here. All of them seem unnecessary, since is tmp is always of 16 size and dc is always of 4 size. If we can't find any matching HorizontalAdd for this, maybe we should consider passing tmp as a pointer and and indexing dc with Unsafe.* stuff.
There was a problem hiding this comment.
yes it is the same as Ssse3.HorizontalAdd, good catch
| [MethodImpl(InliningOptions.ShortMethod)] | ||
| public static void YuvToBgr(int y, int u, int v, Span<byte> bgr) | ||
| { | ||
| bgr[0] = (byte)YuvToB(y, u); |
| #if SUPPORTS_RUNTIME_INTRINSICS | ||
| if (Sse2.IsSupported) | ||
| { | ||
| tmp.Clear(); |
There was a problem hiding this comment.
Is this really needed? We override the contents in the end.
There was a problem hiding this comment.
yeah i think you are right, its not needed
Reverse access to dc Co-authored-by: James Jackson-South <[email protected]>
| dc[3] = (uint)lower.GetElement(3); | ||
| dc[2] = (uint)lower.GetElement(2); | ||
| dc[1] = (uint)lower.GetElement(1); | ||
| dc[0] = (uint)lower.GetElement(0); |
There was a problem hiding this comment.
I'm not sure what does GetElement compile to but it can be terribly inefficient. dc[0...3] is 64 bits if I'm not mistaken:
| dc[3] = (uint)lower.GetElement(3); | |
| dc[2] = (uint)lower.GetElement(2); | |
| dc[1] = (uint)lower.GetElement(1); | |
| dc[0] = (uint)lower.GetElement(0); | |
| Unsafe.As<uint, Vector64<short>>(ref MemoryMarshal.GetReference(dc)) = lower; |
There was a problem hiding this comment.
No sorry, it's actually 128 bits. It needs some widening with intrinsics then.
There was a problem hiding this comment.
I think this GetLower is not needed at all, now that i think again about it.
What about this: 1452ba0
There was a problem hiding this comment.
@antonfirsov so you think we should try to avoid GetElement entirely?
There was a problem hiding this comment.
I think it's a good practice to avoid GetElement whenever possible. It looks like it compiles to VPEXTRW extracting scalar registers from the SIMD register, but then you do scalar copy for each value. We can get much better results with shuffling:
SHARPLAB
I think we are looking for _mm_unpacklo_epi16 / Sse2.UnpackLow interleaving lower with zeros to get equivalent uint values, but not sure how would this act with negative short-s. Can hadd end up having negative values?
Sse2.UnpackLow(lower, Vector128<short>.Zero)There was a problem hiding this comment.
That looks indeed much better. I dont think there can be negative values.
Thanks for your help!
There was a problem hiding this comment.
using Sse2.Store looks even a tiny bit better. Should I go for that?
There was a problem hiding this comment.
dc is stackallocked, so you can pass it as a pointer easily if you want to, though I'm not sure if it's worth the trouble.
The main benefit would be the removal of one Slice() on the call site, the disadvantage is the inconsistency of the method signature (input is a span, dc is a pointer).
There was a problem hiding this comment.
I think its not worth it, lets keep the method signature consistent and keep it as it is.
Prerequisites
Description
This PR add SSE2 version of Mean16x4 which is used during lossy encoding with mode 1.
Related to #1786
Profile Results
Before:
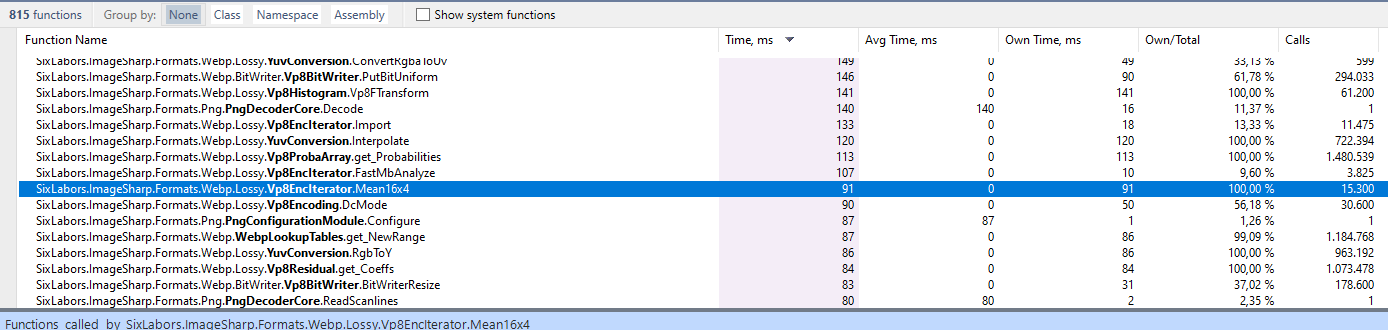
After:
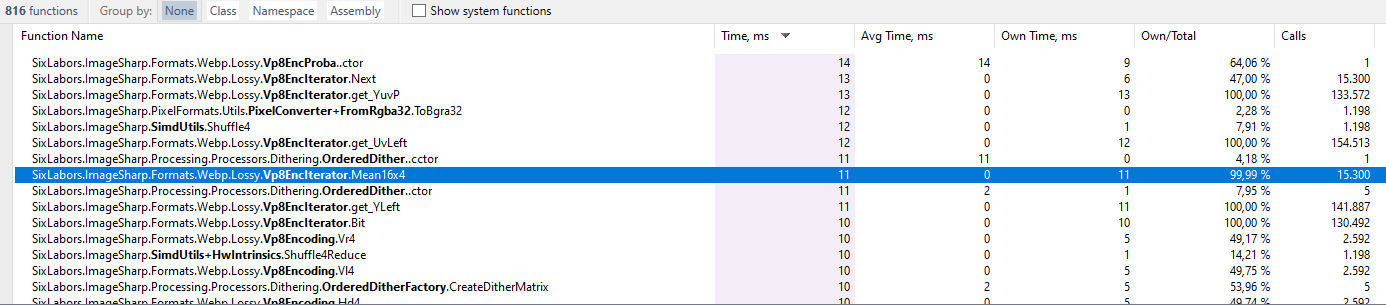
The overall encoding time was 9002 ms.
Its an improvement, but only a small one. I guess every bit counts.