Windows/Arm64: Use 8.1 atomic instructions for GC code #71169
Conversation
|
@Maoni0 @dotnet/jit-contrib |
|
Tagging subscribers to this area: @dotnet/gc Issue DetailsFollowing the example of #70921, continue to optimize following APIs using
I was not able to optimize more methods because of lack of MSVC having them available. I have opened https://developercommunity.visualstudio.com/myfeedback?space=62&q=intrinsic&entry=myfeedback to make a suggestion. I couldn't even write assembly equivalent for them because MSVC doesn't handle 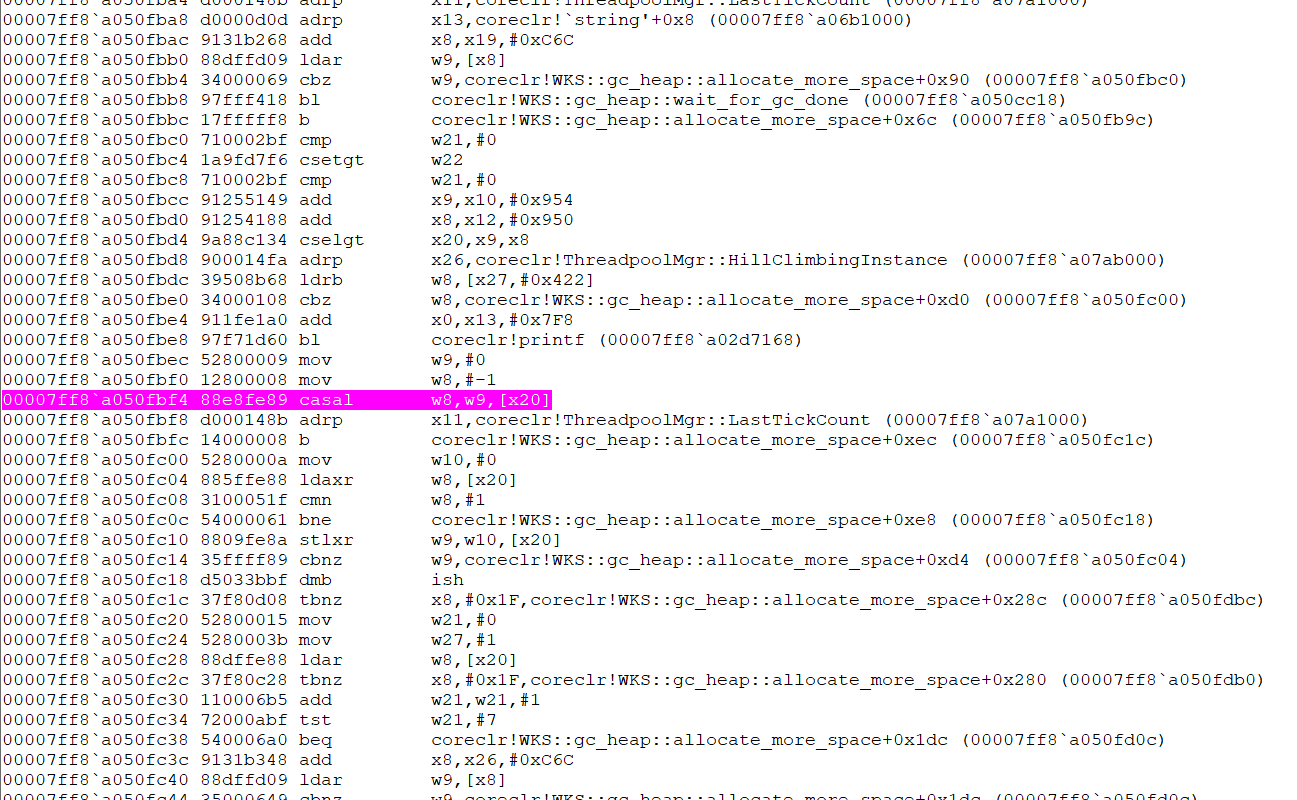
I have declare/defined
|
|
Any measurable perf improvements from this change? |
|
To fix the NativeAOT build break, you can define and initialize the flag here: |
Oddly no. I tried measuring using GCPerfSim. The numbers are in error margin and so I don't see much impact. @Maoni0 - any other benchmarks you would recommend? I intentionally didn't set
|
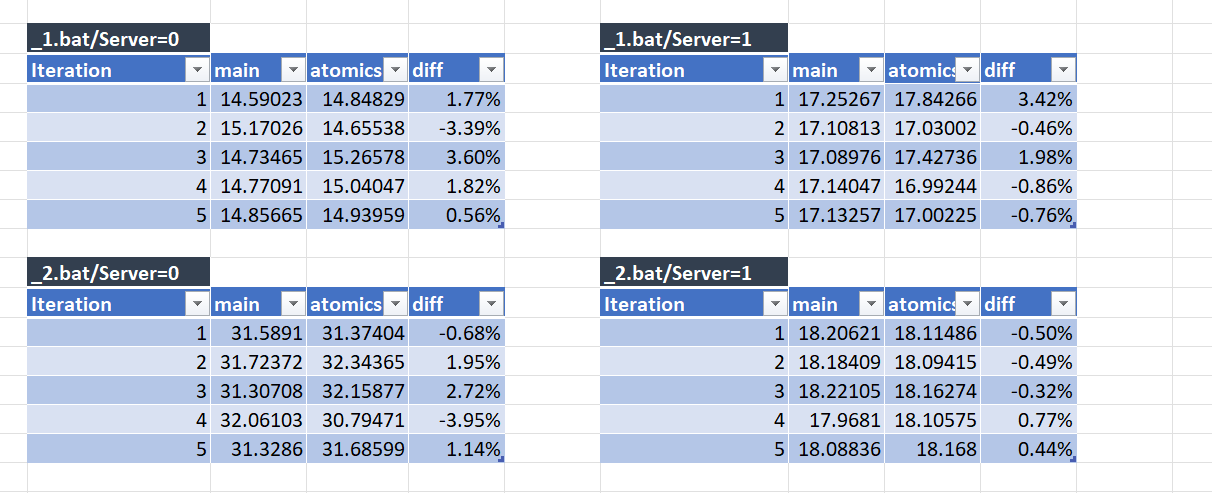
It is what I would expect as we have discussed offline. The GC should not be doing interlocked operations that often for this to make a measurable difference. I was more wondering whether there is a path through GC where this would make a measurable difference that I did not think about. |
Right, but @Maoni0 did point out some interesting code paths like |
How much time do the GC benchmarks spend in these methods? Subtract the time spent spinning from that. The expected benefit will be 20% of what remains based on the data from your other PR. |
|
you are not going to detect the difference by measuring the total execution time. if you make it so that it hits the code path like enter_spin_lock a lot more, you could potentially detect difference by looking at the CPU sample counts. right now you are using |
|
I don't see much difference with
However, when I checked at instruction level, I did see code around compareexchange to be hot.
Do we think we should still do this or as Jan pointed, since there won't be measurable difference skip doing it? |
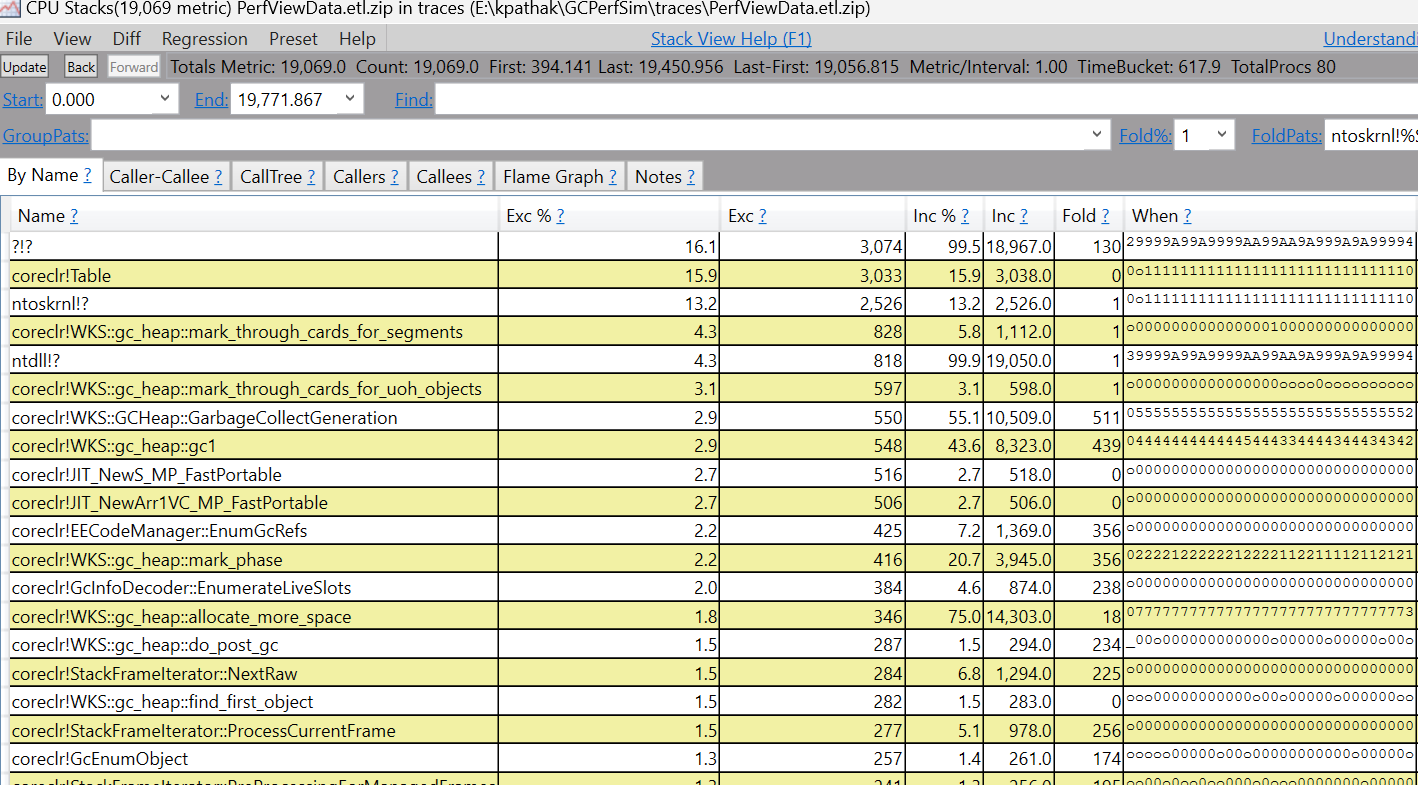
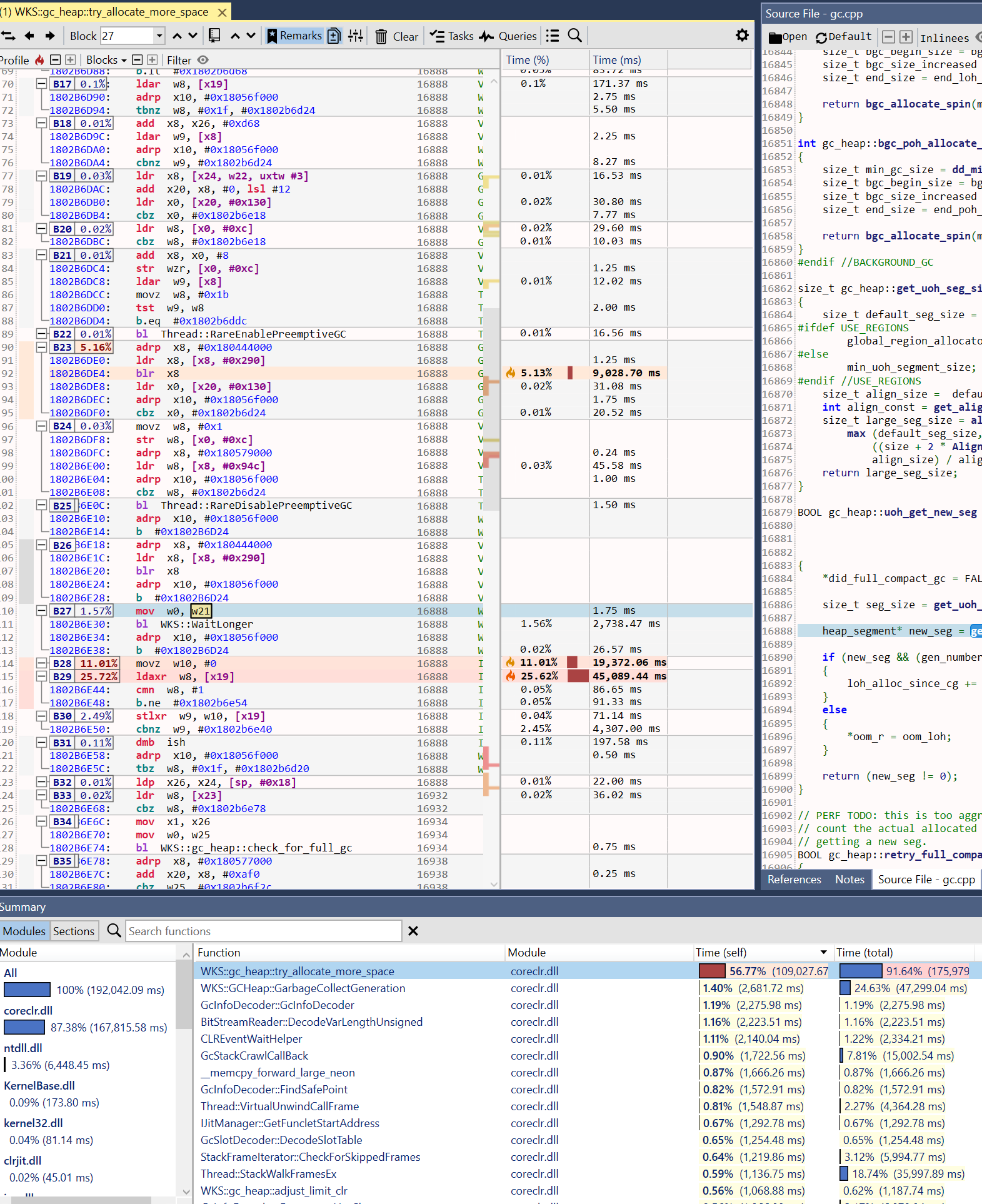
|
I should have been more clear - this is not going to show up as a top method or anything. I meant you'd need to actually look at the CPU sample count that's spent in enter_spin_lock which is inlined so this would be in I could skip doing this for GC. |
Sounds good to me. I am testing another prototype in #71260 which should enable using atomics on linux/arm64 on machines that have capability. On windows, we will live without it. |
Following the example of #70921, continue to optimize following APIs using
atomicsin GC code base for Windows/arm64:I was not able to optimize more methods because of lack of MSVC having them available. I have opened https://developercommunity.visualstudio.com/t/Add-APIs-for-Arm64-intrinsics-for-_Inter/10078117?space=62&q=intrinsic&entry=myfeedback to make a suggestion. I couldn't even write assembly equivalent for them because MSVC doesn't handle
__asmfor arm64 and writing the method in a.asmwill invoke a function call, while we want these APIs to be inlined.I have declare/defined
g_atomics_available_presentforclrgcandgcsamplebut not setting them, so it will be OFF by default for them.