- Free computing using esProc
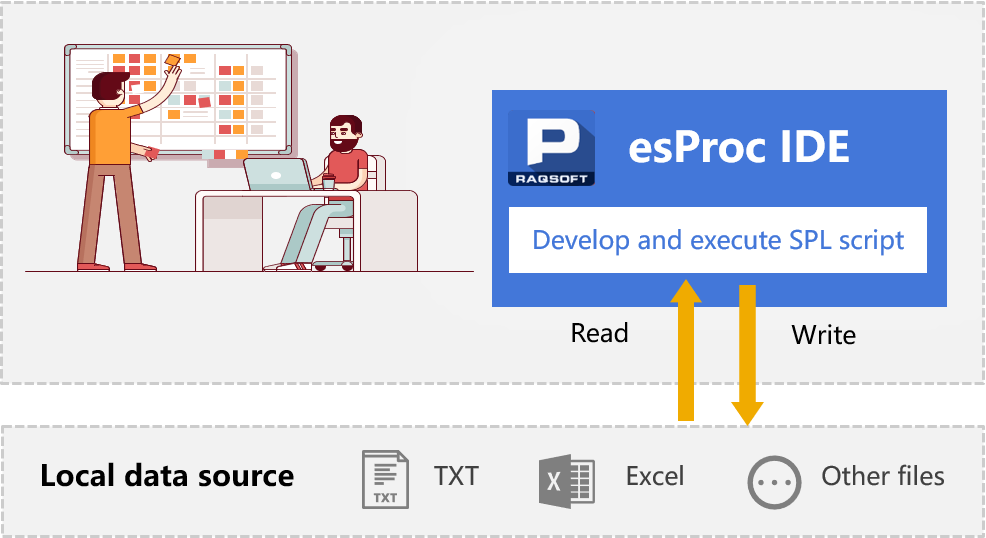
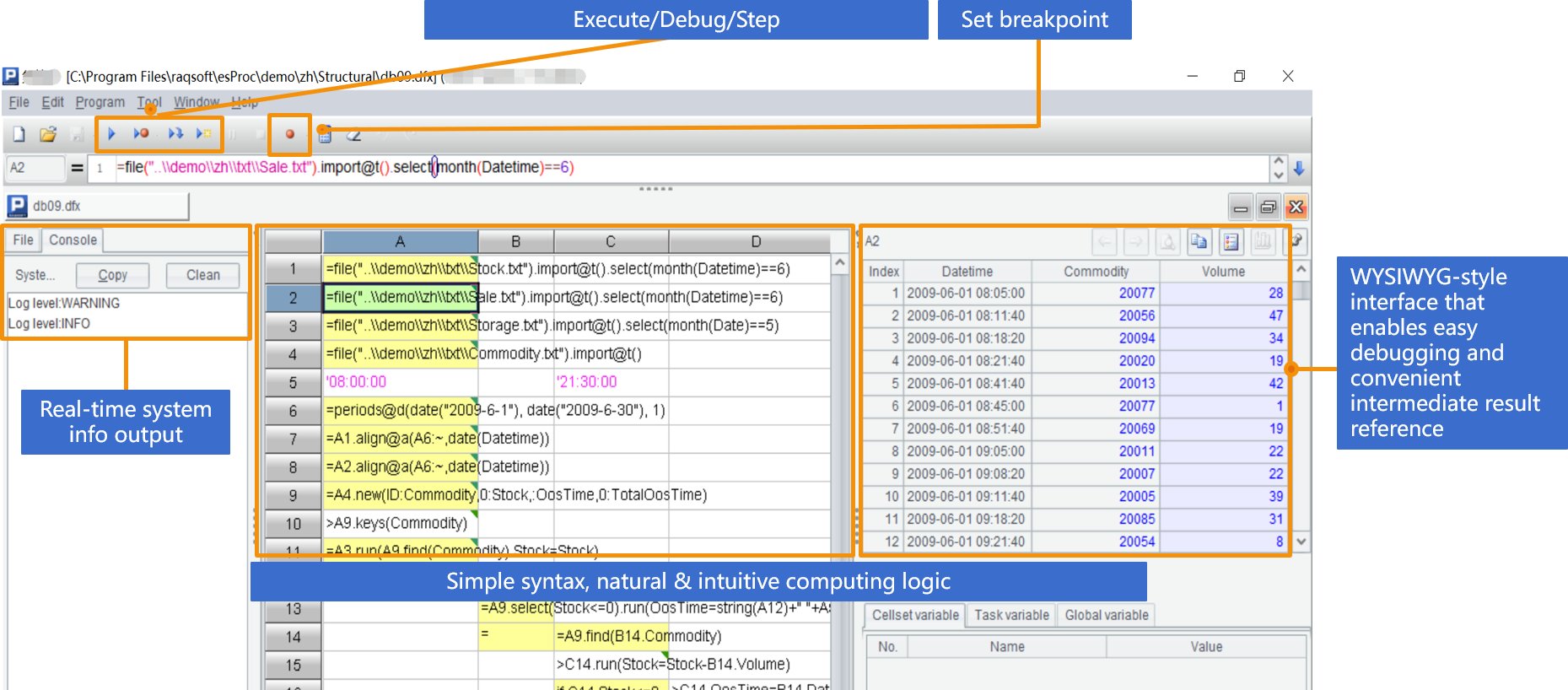
- Convenient development environment
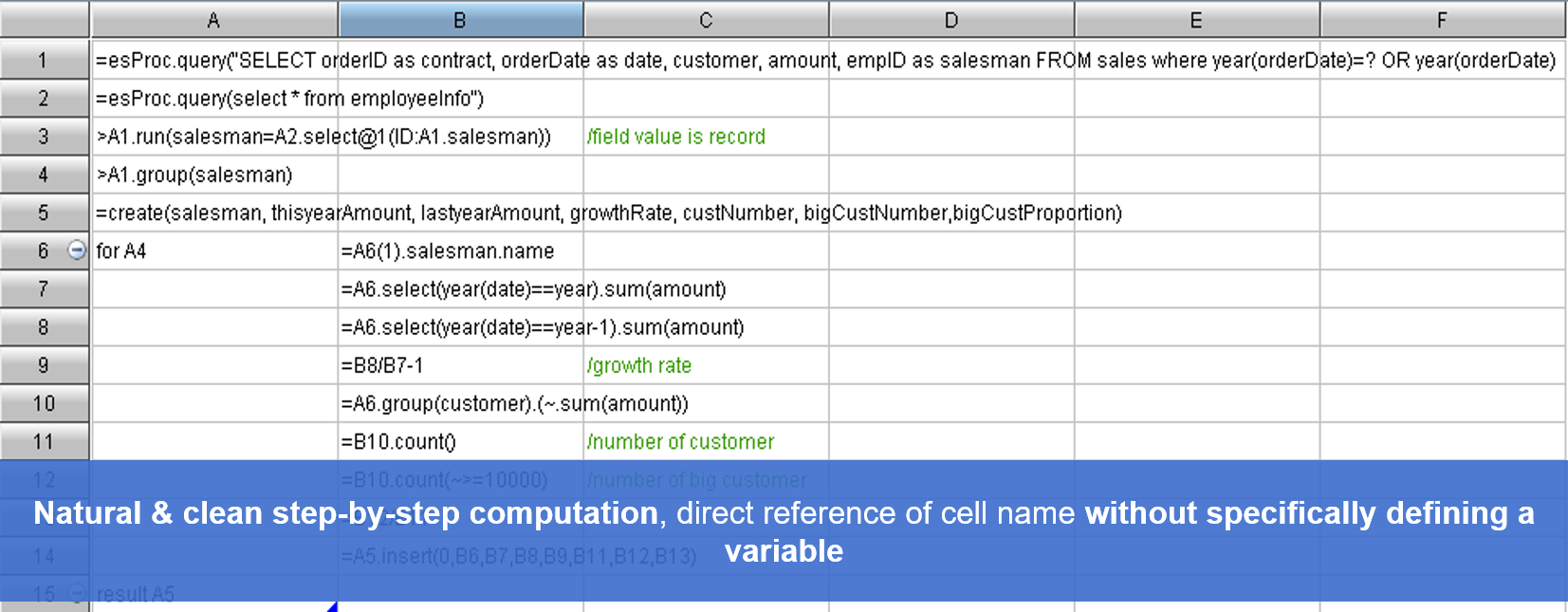
- Syntax suitable for describing a natural way of thinking
- Far more accessible than Python
Example:Sorting and filtering of grouped subsets
Task: Find out the sales clerks whose sales are within top 8 for every moth in 1995.
Python script:
import pandas as pd
sale_file = ‘E:\\txt\\SalesRecord.txt’
sale_info = pd.read_csv(sale_file,sep = ‘\t’)
sale_info[‘month’]=pd.to_datetime(sale_info[‘sale_date’]).dt.month
sale_group = sale_info.groupby(by=[‘clerk_name’,‘month’],as_index=False).sum()
sale_group_month = sale_group.groupby(by=‘month’)
set_name = set(sale_info[‘clerk_name’])
for index,sale_g_m in sale_group_month:
sale_g_m = sale_g_m.sort_values(by=‘sale_amt’,ascending = False)
sale_g_max_8 = sale_g_m.iloc[:8]
sale_g_max_8_name = sale_g_max_8[‘clerk_name’]
set_name = set_name.intersection(set(sale_g_max_8_name))
print(set_name)esProc SPL script:
| + | A |
|---|---|
| 1 | E:\txt\SalesRecord.txt |
| 2 | =file(A1).import@t() |
| 3 | =A2.groups(clerk_name:name,month(sale_date):month;sum(sale_amt):amount) |
| 4 | =A3.group(month) |
| 5 | =A4.(~.sort(-amount).to(8)) |
| 6 | =A5.isect(~.(name)) |
With basic programming knowledge, you can calculate files freely, self-service and quickly!