runtime: repeated syscalls inhibit periodic preemption #28701
Comments
|
Gathered some evidence that this isn't related to preemptibility. Here's a trace of a good run:
And here's a trace of a bad run:
Besides the vastly different time scales (130ms vs 90s), one other big difference stands out. The good run slowly increases the number of threads in syscalls towards 100 as the number of sleeping goroutines grows to 100. This is what allows the non-sleeping goroutines to make progress. In the bad run, the number of threads is fixed at eight, and so the sleeping goroutines hog the Ps and grind everything to a halt. |
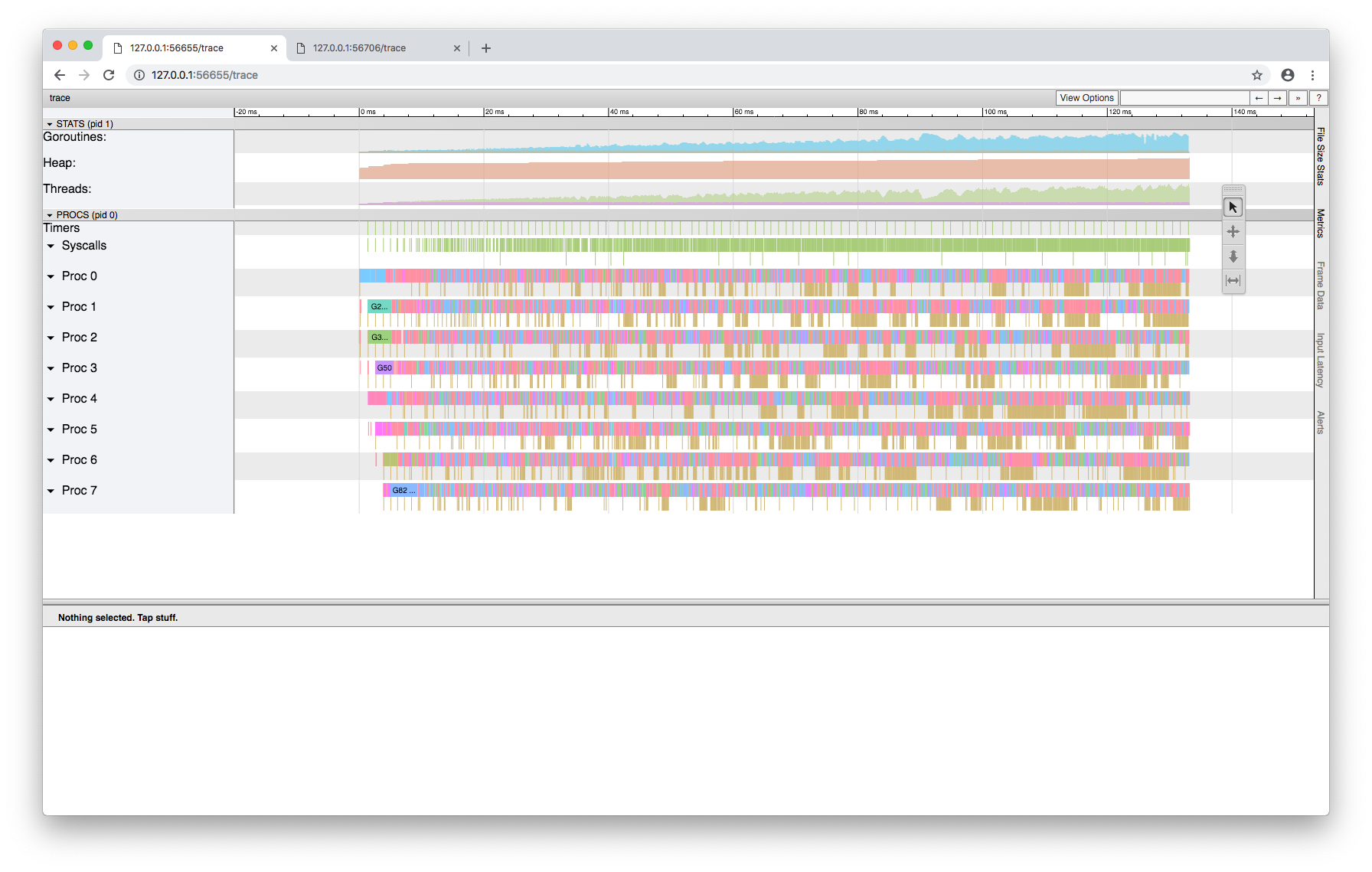

|
Try to add some debug logging to retake function, it is supposed to retake Ps blocked in syscalls. Does it run? Does it see Ps in syscalls? Why does not it retake them? Or does it retake them but they don't run new goroutines somehow? |
|
Huh, it appears not to be retaking them at all. With this patch diff --git a/src/runtime/proc.go b/src/runtime/proc.go
index 864efcdfed..f236f36a5e 100644
--- a/src/runtime/proc.go
+++ b/src/runtime/proc.go
@@ -4413,6 +4413,7 @@ func retake(now int64) uint32 {
// Otherwise the M from which we retake can exit the syscall,
// increment nmidle and report deadlock.
incidlelocked(-1)
+ println("retaking ", _p_.id)
if atomic.Cas(&_p_.status, s, _Pidle) {
if trace.enabled {
traceGoSysBlock(_p_)I see a continual stream of retaking messages: In a bad run I see no retaking messages at all. Digging in further now. |
|
sysmon can completely block and stop doing anything, if it thinks there is nothing for it to do. But exitsyscall should wake it. |
|
Yeah, I added some logging to the beginning Lines 4397 to 4402 in e496e61 In bad runs we see that these ticks are permanently misaligned: |
|
Oh, this is fascinating. If the sysmon delay creeps up to 10ms, I think the solution is actually pretty simple. We need to consider Ps in syscalls for preemption based on schedticks, and not just syscallticks. |
|
If retake sees that a P makes constant progress executing syscalls, then it must not retake it. It's meant to retake Ps from syscalls blocked for a long period of time. If a goroutine is running, making progress and returns from all syscalls in a timely manner then it should continue to run. What's failing here seems to be goroutine preemption, the next check in retake ( |
|
Ah, yeah, sorry I wasn’t more clear. Considering that P’s G for preemption,
not retaking the P itself, was exactly what I had in mind. This is somewhat
complicated because a P does not maintain a reference to its M/G while it
is in a syscall.
Perhaps we should add an oldm to a P to mirror the oldp field that I have
in my (unsubmitted) next CL.
…On Fri, Nov 9, 2018 at 5:45 PM Dmitry Vyukov ***@***.***> wrote:
If retake sees that a P makes constant progress executing syscalls, then
it must not retake it. It's meant to retake Ps from syscalls blocked for a
long period of time. If a goroutine is running, making progress and returns
from all syscalls in a timely manner then it should continue to run.
What's failing here seems to be goroutine preemption, the next check in
retake (s == _Prunning). The goroutine is running for too long, but we
don't preempt it, since we don't see P in _Prunning state (right?). What if
we try to retake P for _Psyscall status, and then, if that fails, try to
preempt it for s == _Prunning || s == _Psyscall?
—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
<#28701 (comment)>, or mute
the thread
<https://github.com/notifications/unsubscribe-auth/AA15IKRxrwnxtrVmjmxAu14YkLZKoN88ks5utgWggaJpZM4YXiAe>
.
|
|
Speaking of which |
|
Yes, preemptone would require keeping p.m (or p.oldm). |
|
Change https://golang.org/cl/148901 mentions this issue: |
|
@dr2chase, @aclements: is it important to include the fix for this in 1.12 alongside #10958? If not, should we mention the caveat in the release notes? |
|
Given that this has been a bug for quite a while, I'm not too worried about fixing it in 1.12 (obviously it would be nice to). CL 148901 seems rather complex and could have performance implications. Have we considered not clearing |
What version of Go are you using (
go version)?Does this issue reproduce with the latest release?
Yes.
What operating system and processor architecture are you using (
go env)?go envOutputWhat did you do?
Ran the following program repeatedly.
The program usually completes in 100ms, but occasionally takes upwards of 60s, and sometimes more than 10m (i.e., maybe it never completes). It appears to be caused by the scheduler starving out the outer goroutine, as uncommenting the runtime.Gosched call makes the test pass reliably in under 60s.
It's possible that this is #10958, but I think that the call to
ctx.Err()should allow for preemption, as should the call into cgo. I'm filing as a separate bug so I have an issue to reference when I add this test in http://golang.org/cl/148717. I'll dig a little deeper in a bit./cc @dvyukov
The text was updated successfully, but these errors were encountered: