Dashboard menu (table of contents) redesign to be driven by OpenTelemetry standards #354
Description
The way our dashboard menu is currently built, relies on the chart names. This is hugely problematic, and for years I have been considering it "my shame".
So, I have been discussing OpenTelemetry with @ilyam8 and we were doing some diagrams on the wall:
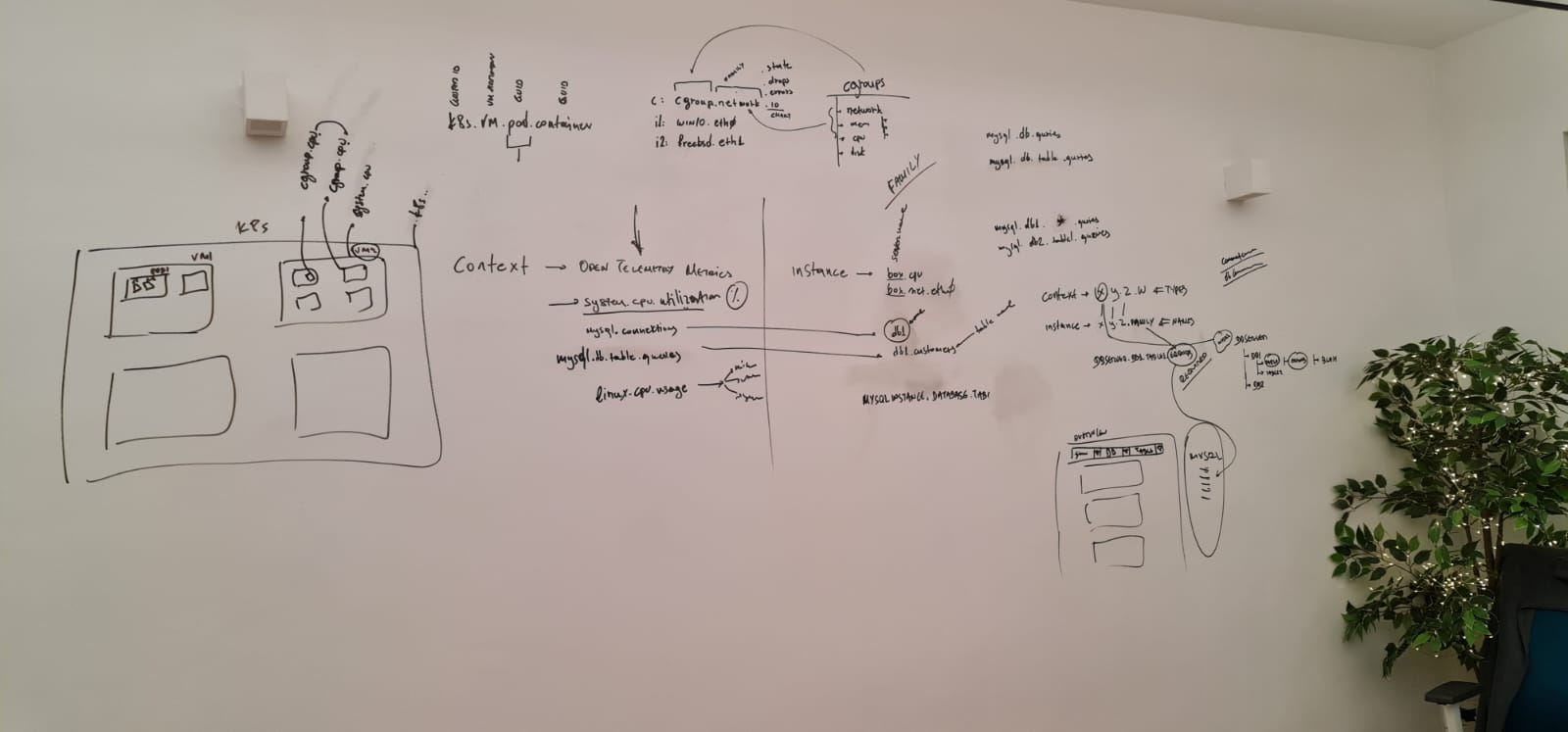
I think we have a viable solution to re-use context in a way that will bring netdata a lot closer to OpenTelemetry and will also allow us to come with a much better logic for creating the table of contents of the dashboards.
A logic that may also fix #351 and #347 and probably will eliminate a ton more bugs waiting to be found.
To validate the above assumption I need the following export from the charts on the cloud:
| chart_id | chart_name | context | family | plugin | module | units | count |
|---|---|---|---|---|---|---|---|
| - | - | - | - | - | - | - | the number of charts with this combination |
@papazach is it possible to have this export?
Metadata
Metadata
Assignees
Type
Projects
Milestone
Relationships
Development
No branches or pull requests
Activity
ktsaou commentedon Mar 19, 2022
The OpenTelemetry Timeseries Model, is like this:
In netdata the
Metric Nameis thecontext. This is also done in our prometheus exporter, where the metrics we send are actually the contexts, with attributes/labels our dimensions. Example:Changing the context
The
contextin netdata is something easy to change. It is only used:Changing the
contextwill have minimal impact on backwards compatibility:alarm templates created or edited by our users may need to be updated
This can probably be automated, by automatically changing all custom or edited alarms to the new contexts.
grafana dashboards created by our users based on our prometheus export may need to be updated
Although this cannot be automated, we supply a map of
oldandnewcontexts for our users to quickly adapt their systems.How we should change the context
OpenTelemetry Metric Semantic Conventions provide some guide on how metric should be named:
limit - an instrument that measures the constant, known total amount of something should be called entity.limit. For example,
system.memory.limitfor the total amount of memory on a system.usage - an instrument that measures an amount used out of a known total (limit) amount should be called
entity.usage. For example,system.memory.usagewith attributestate = used | cached | free | ...for the amount of memory in a each state. Where appropriate, the sum of usage over all attribute values SHOULD be equal to the limit.A measure of the amount consumed of an unlimited resource, or of a resource whose limit is unknowable, is differentiated from usage. For example, the maximum possible amount of virtual memory that a process may consume may fluctuate over time and is not typically known.
utilization - an instrument that measures the fraction of usage out of its limit should be called
entity.utilization. For example,system.memory.utilizationfor the fraction of memory in use. Utilization values are in the range [0, 1].time - an instrument that measures passage of time should be called
entity.time. For example,system.cpu.timewith attributestate = idle | user | system | ....time measurements are not necessarily wall time and can be less than or greater than the real wall time between measurements.time instruments are a special case of usage metrics, where the limit can usually be calculated as the sum of time over all attribute values. utilization for time instruments can be derived automatically using metric event timestamps. For example,
system.cpu.utilizationis defined as the difference insystem.cpu.timemeasurements divided by the elapsed time.io - an instrument that measures bidirectional data flow should be called
entity.ioand have attributes for direction. For example,system.network.io.Other instruments that do not fit the above descriptions may be named more freely. For example,
system.paging.faultsandsystem.network.packets. Units do not need to be specified in the names since they are included during instrument creation, but can be added if there is ambiguity.The above are great, but they do not address another key parameter. How to name
entities.Netdata should have semantics for entities too
Naming entities is crucial to provide clarity in the monitoring platform. Take for example the
system.memory.usageexample given in the OpenTelemetry definition above:system.memory.usagewill have attributes/dimensionsfree,used,cacheandbufferssystem.memory.usagewill have attributes/dimensionsfree,active,inactive,wiredandbuffersHaving non-uniform dimensions under the same metric, will make aggregations impossible, wrong or error prone.
We could have this:
system.memory.usagewithvariation: linux, the linux onesystem.memory.usagewithvariation: freebsd, the freebsd onesystem.memory.usagewithvariation: macos, the macos onesystem.memory.usagewithvariation: windows, the windows oneA similar situation my arise when the same application, after some version enriches its metrics. So, let's assume that application X, has memory
usedandcachebut in app version 2 they break downcacheindata cacheandindex cache. How can we notify the users that 2 versions of the same metric exist and how we can set different alarms for each version? Having avariationfield could help in that.In time, all kinds of variations may happen:
To solve this problem Netdata alarm templates are already doing something similar, by filtering by
os: https://github.com/netdata/netdata/blob/cabf89dfebb5441e2249760fde14afdb3739c91c/health/health.d/timex.conf#L7This is however inefficient. What if we needed to apply a different alarm based on mysql version?
Having a more generic mechanism (whatever may change the attributes/dimensions and therefore the meaning of a metric) seems a lot better. So, we may say that
mysql.memory.usagemay exists withvariation: mysql-1andversion: mysql-2and different alarm templates may match the first or the second.ktsaou commentedon Mar 19, 2022
Using the context to build the table of contents of x-node dashboards
Cross-node, composite, overview dashboards are supposed to be the x-ray of the infrastructure. Today we build the table of contents and we group charts together based on
contextand many heuristics to make it meaningful. But this is becoming increasingly complicated...By changing the
contextfor all charts and adding ascopeto them we may be in position to simplify this logic tremendously, while providing additional clarity to users about the infrastructure they run.So, the menu could look like this (without taking into account the existing
familyfield that groups charts into subcategories):papazach commentedon Mar 22, 2022
Hello @ktsaou I uploaded in our Google Drive the requested export in .csv format (404MB gzipped, 5.4GB original size).
You may find it here.
Feel free to take a look and reach out in case something additional is required.
hugovalente-pm commentedon Apr 21, 2022
the extract above has been loaded to BigQ so that it would then be filtered to have an actual extract on google sheets the file is here
netdata-community-bot commentedon May 11, 2022
This issue has been mentioned on the Netdata Community Forums. There might be relevant details there:
https://community.netdata.cloud/t/group-docker-containers-in-menu/2797/4
[-]Dashboard menu (table of contents) could be built using the context[/-][+]Dashboard menu (table of contents) redesign to be driven by OpenTelemetry standards[/+]hugovalente-pm commentedon May 5, 2023
this depends on https://github.com/netdata/product/issues/3123
5 remaining items