Oops with new kernel when using NFS #88
Description
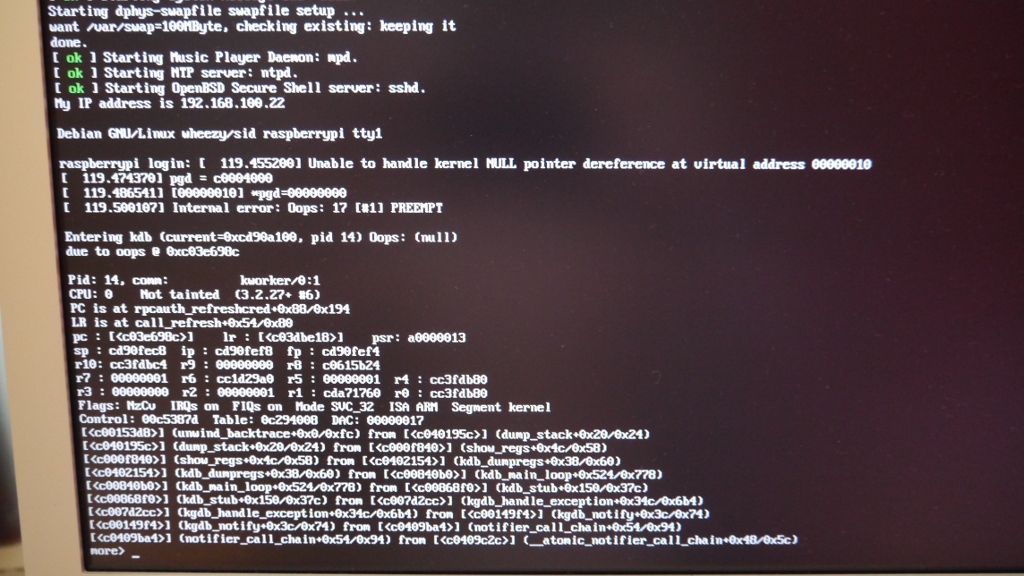
When using the new kernel I get a reproducable oops when using NFS (client). Sometimes it happens fairly quick sometimes it takes a while.
I've taken a screenshot of the oops.
When using the new kernel I get a reproducable oops when using NFS (client). Sometimes it happens fairly quick sometimes it takes a while.
I've taken a screenshot of the oops.
{kind=link}