A New Approach (Experimental) ⚠️ #1276
Conversation
rename refactor and cleanup some tests
… tests related to dispatching in construct, willMount, render as they will not work in SSR with this style of update queue
remove yarn.lock cleanup tracing logic clarify render count in test comment restore pretest script fixup! restore pretest script
|
Deploy preview for react-redux-docs ready! Built with commit d808e84 |
|
Wow. This is a lot to take in :) Absolute first impressions having just barely skimmed this writeup:
|
|
Yeah, it's a bit much :)
likely yes in it's current form. with a better tie-in to synchronously starting the next updater work step when react finishes updating the current one it can get better
the main loss of speed here is that it benefits zero from the lack of dependent updates. the deep-tree benchmark is in particular tough because you have 250 'independent' components which contain zero connected children. I think it is much more common that apps will have connected graphs of nodes that relate to some origin and the perf drop on many commit phases will be balanced out by gains in how efficient those updates are processed In addition, if user idioms for hooks is to use many I've used it in www.fubo.tv and it performs about equal with v7
it was based on master since there isn't really much overlap with the current Subscription approach. it does implement the 3 public hooks apis. It does drop support for providing custom context to connected components during render (you can still provide custom context when you construct the connector) no rush here, I don't necessarily think this will ever get merged. But I thought it worthy of investigation and discussion since it does unblock one key downside to all existing useSelector hooks implementations |
|
This looks certainly very interesting. As you may know I have spent some time recently thinking about this and I'll definitely take a closer look at this in the next couple of days. I haven't looked at much of the code yet, but I remember discussing the idea of notifying components in render order somewhere before, and our conclusion was that it won't work (I believe it was this discussion). Not sure if all those points apply here though, and it would be great if it turns out I was just missing something. I'll make sure to look at the code thoroughly. EDIT: lol, I accidentally deleted my comment when trying to edit it, so I tried to re-create it |
|
@MrWolfZ I think the only thing different is that I didn't accept that waiting for commit was too slow. I agree concurrent react support is unlikely in it's current form and there are certainly edge cases I didn't cover like what if a component schedules an update (setState) during render for a component deeper in the tree that hasn't already yet rendered. in sync react this package does not relinquish control back to the browser to do layout and rendering until it has flushed updates for all components, though I have not tested what happens if you for a layout by mutating a dom property that requires for instance. Lots of edge cases for certain. |
|
You can try wrapping some tests in a And I don't think this will work whenever low-priority updates land. At that point, new components can get created out-of-order, so you won't be able to rely on execution order to construct a properly-ordered queue. Of course, since this is all still very much in flux, maybe it won't be so bad. Who knows? 🤷♂ But I'd rather wait to know for sure what those APIs and behaviors are going to look like before making assumptions. As for the (non-con)current state of the world, I think this looks good. I think the deep tree issue is actually a bit of red herring. The incremental commits could prevent some hitching when it comes to actual UX, whereas a giant batch may span several frames and cause a visible slowdown to users. Of course, I could be wrong and confusing what Fibers are actually getting created and run here. I'm not the greatest React internals expert... |
|
Thanks @timdorr
The order doesn't matter in general, it is simply important that children are created after their parent is created and even with concurrent mode and suspense I believe this has to be true. The only time this might be violated is if React added reparenting support that did not recreate new fibers (I think)
what do you mean by hitching? Also based on the work loop getting recalled in microtask queue control is not given back to the browser to do a paint until work is exhausted so as it stands now frames will take just as long whether we batched everything up or do it incrementally. We could allow for a pause to let the browser render but then we would be painting a partially updated UI which could get really strange really quickly.
I agree, I think this particular component structure is about the least efficient possible structure we could encounter with this technique and it still holds up pretty well. The moment you start having connected children rendered by connected parents the efficiency gains of the single pass work loop start making up for the extra commit phase costs paid by many tiny tree updates Thanks for taking a look |
The CPU part of Dan's turtleneck talk: https://www.youtube.com/watch?v=nLF0n9SACd4 |
|
@gnoff What if we could use react currentOwner to detect whenever current sequence is just sequence in the same component. So we will need to update A->B if A.component and A.component is different components. Or this info doesn't affect your implementation ? |
|
ReactCurrentOwner is a pretty internal thing for React (it's on ReactSharedInternals, after all). I'd rather no rely on that, since it's not a public API. |
|
Yeah, anything that really starts digging into React's internals is likely going to be a non-starter, except as an experiment. |
|
@zmitry the cool thing is it doesn't matter if the components are the same. the evaluations are lazy so it will check each selector instance until something needs to do work. the remaining ones for a given component (if any) would run when the component rendered. @timdorr @markerikson This PR is interesting but a bit too fragile I think since it wants deep coordination with react's scheduler and can't really get it. On top of that with all the ref usage and the fact that updates are propagated in pieces to the tree we can't really say that it is concurrent react ready. I've been working on an a proposal and PoC implementation for a change to the react Context apis that might give us proper concurrent support + high performance. It would actually eliminate the core subscription and update mechanism of this library with the Provider + useSelector coming in at around 20 lines of code. I'm happy to keep this open if it's useful to inspire discussion and thinking but given it is not likely to be merged I'm happy to close it to clean up the PR list |
|
@gnoff : yeah, I'm inclined to agree. I certainly appreciate the idea of trying to re-think the implementation in general. Please ping me if/when you actually file a PR for React's context implementation. I'd love to see that. |
Friends,
I've come bearing gifts 🎁
I was bothered by the fact that the upcoming useSelector hooks are going to potentially have to suffer the zombie child problem. A problem likely exacerbated by new apps that never use connect and therefore do not create Provider sub-trees where subscriptions are nested. So I decided to see what I could do about it. In the process I came up with an experimental, novel, high performing approach to driving state updates into components that I think has a lot of value even outside top-down updates
I've been using this library since it's inception and in the early days helped get what is more or less the core of the connect API implemented way back in v0.5.0. This new work however touches none of the public API but completely rewrites the state updating mechanism.
Summary
This new updater implementation...
useSelectoruseSelectorimplementation to implementconnectby way ofconnectAdvancedTerminology
with the advent of
useSelectorit is hard and imprecise to use the word "Component" when talking about an updatable unit. a component can have more than oneuseSelectorand the thing that is updatable is the hook in this case not just the containing component. To generalize the discussion I've started calling any thing that needs to respond to state changes as anode. so a connected component will have one node (because connect only uses oneuseSelector) and components with manyuseSelectorcalls will have many nodesEnsuring Order of updates
There are two main issues with allowing a connected component to update before it's parent
these issues only affect a percentage of connected components but the library can eliminate them as problems and it should
The real constraint
On the surface it appears top down is what is required and therefore we may need a tree representation of our nodes or a depth value to be able to trigger updates in some kind of cascade. this is currently infeasible given lack of visibility into where you component sits in the React tree. In addition, given that a node is not one-to-one mapped to a component, the node hierarchy is not identical to the React tree hierarchy. However we don't actually need the tree or the depth, we just need to ensure that all preceding nodes in the current component and all nodes in any parent component have already been checked and, if necessary, updated.
this constraint can be satisfied by a simple singly-linked-list appended in the order of hook execution
imagine we have nodes
A -> Bthese could be
uS(A); uS(B);C(A) -> C(B)[C(A), C(B)]however they cannot be
uS(B); uS(A);C(B) -> C(A)in the two above cases B would come into existence before A and the queue would enforce a structure as
B -> Athe amazing thing is this composes across multiple render cycles.
imagine starting with
[null, C(A)]and then on an update rendering[C(B), C(A)]. the queue would still beA -> Band we can still guarantee that B does not depend on A since it exists in a sibling branch of the component hierarchyyou can keep appending new nodes when you first encounter them in a render and you will maintain the following invariants
So regardless of whether we go top down or not, as long as we work on nodes from the front to the back of the list in order we can provide the essential guarantee that will avoid zombie children / wasted update checks / wasted additional renders
How does it work
every useSelector constructs a node at initial render. the node contains an update function which our updater can use to schedule an update if required
The Updater maintains the node queue and manages a work loop. Every work step it processes the node queue from where it ended the last step. it purges nodes from unmounted components, it skips nodes that have already been updated by a parent, and it checks nodes that haven't to see if they need to trigger an update in React. a work step ends when there are no more nodes to process or a node indicates it has scheduled an update
If React is now processing an update a new work step is scheduled to run after React finishes
Testing
So far I have not written new tests and with modification to the tests most existing tests pass. the remaining tests that do not pass probably shouldn't because they are no longer valid and investigation needs to be done to decide whether the test case should be retained
The key difference is that react-dom's
actfunction does not hold onto control long enough for updates to flush. Using the new async support in[email protected]we can get around this for most cases just by making the assertions execute on a microtask following the updater's work. however with many synchronous dispatches in a row it can require more time awaiting. A new option is probably warranted to make testing this more resilient, essentiallyawait allUpdatesHaveFlushed()Edge Cases and Undecided things
Certain things are not settled, for instance
(How) is this fast?!?
There are certainly a few things about this approach that are slower than a traditional subscription based approach that can take advantage of batched updates. That said there are counterbalancing factors that make this approach faster in many ways. When I've benchmarked the performance using react-redux-benchmarks some perform slower than v7, some are faster, and many are just about equal. It is way faster than v6 in every benchmark and v5 in most benchmarks
That said, I'll go through some of the specific ways and reasons why this is slower or faster than the conventional approach. Some of these things may be improvable today, many will be improvable with more advanced queue walking algorithms, and even more still if React itself provides new apis that optimize for this kind of interplay between externalized data updates
Commit phase / React tree traversal costs
When you batch updates React has an opportunity to walk the fiber tree and perform more than one update before committing it. committing requires a walk back up the tree (I believe, please correct me if I am wrong here) and so there is an underlying cost to commits regardless of how many fibers were updated. it's not completely this straightforward b/c the tree is only walked as deep as needed for the fiber update that is processed (and any child fibers that update as a result) but by processing a single node at a time we opt into a commit phase per updated node
here is v7 batching 50 updates together. it does it in one reconciliation step followed by one commit phase

here is this implementation doing 1 update at a time (50 times in a row). ignore the apparent time differences here since they are not scaled consistently but the cost of each commit phase can add up to a drag on performance. this explains the FPS drop in the deep-tree benchmark included in the addendum
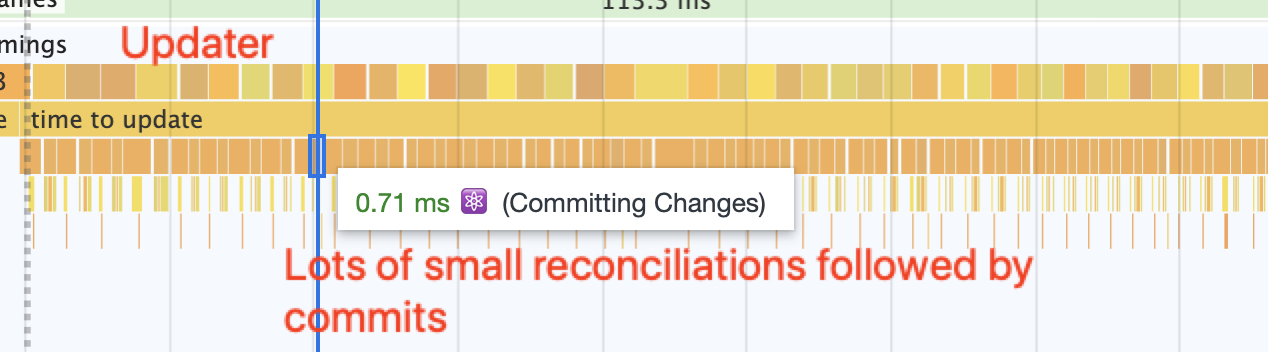
No unnecessary updates
On the other hand this new process eliminates the need for extra work like
checkForUpdatesandnotifyNestedSubs. If a parent sub renders children and then notifies that child of state update, even if the update is quick and bails out it still has to do work. by driving updates from an Updater that guarantees all states will flush to components eventually we don't need to even run the update function on some nodes since if it renders in a ancestor update we already know it is caught upOther Benefits (non-performance)
aside from performance we have these other great benefits
store is not read in render
By avoiding reading the store in render we get closer to concurrent react support. nodes will always read the currently updating state even if new states have been emitted by our store subscription. If we start putting the state in fiber itself we can get all the way towards consistency.
intermediate states are dropped consistently
even though the updater executes work on microtasks and therefore is not fully synchronous we do not run into issues of having different states seen by components part way through an update. I'm not certain this can happen in current 7.0 implementation but reading state from the store suggests it is possible (especially in concurrent react mode)
Other experiments to try
These aren't part of this PR but the new architecture can allow for us to try these things
see if sync updates can happen without hitting 50 re-render limit
If react allowed for unlimited re-renders (in certain circumstances) we can switch to mode that executes the next node update synchronously after the previous update commits. this can make issues around timing our next work loop on a microtask more resilient. for instance microtasks don't work correctly in certain older versions of Edge and IE. And while as long as we match the cadence of react work updates we might be ok this is tenuous and a more explicit handoff of "React is done -> next update work step begins" would be more resilient across other browser versions
try a mode that optimizes 60 fps
If we are ok painting partial updates we can chunk the update across multiple frames using requestAnimationFrame. the specific order of updates is not guaranteed (siblings appearing before others may update after their later siblings) so it could lead to some odd UI experiences and since concurrent react is solving the 60 fps problem itself this is unlikely to actually be desirable but it is an interesting option nonetheless even if just to play with
implement dynamic batching
if we assume every node is connected to every other we have to process them one at a time. however there are ways we can discover disconnected node segments by a few basic heuristics and it is possible to build up a list of many independent batch queues that could in theory by worked concurrently in each update work step. this might take the performance over the top however there are many more complicated edge cases in particular with Contexts that trigger updates in deep children
Addendum
Benchmark results