Switch from kuchiki to LOL_HTML #930
Conversation
Before, it was generating code like this: ```html <div class="rustdoc mod" container-rustdoc="" id="rustdoc_body_wrapper" tabindex="-1"> ``` Now it generates code like this: ```html <div class="rustdoc mod container-rustdoc" id="rustdoc_body_wrapper" tabindex="-1"> ```
|
Going to try this on the 300 MB file and see what happens. |
- Inline `navigation.html` into `body.html` - Remove `page.html`
|
Once cloudflare/lol-html#56 is fixed, we could also remove |
The way the new LOL rewriter works requires a valid <head> and <body> tag. I think it's pretty safe to assume any HTML generated by rustdoc will have at least those. However, much of the test suite did not, because it was using random content like `b"lah"`. This adds a default HTML content which both makes it easier to write tests and makes the content valid HTML by default. A new function `rustdoc_file_with` was added in case you still need the old behavior.
It worked 🎉 🎉 🎉 Took about a minute to serve then another 5 to load but that's to be expected :) |
|
It used ~350 MB of memory to serve which seems about right. |
There was a problem hiding this comment.
This looks like a really great change, makes me wonder if we shouldn't add a time limit of some sort later on down the line to prevent us getting swamped (alternatively having a higher size cap would probably work, letting us not even try to parse files that are over x MB). You may need to update the benchmarks, and I'd be really interested to know if there's a speedup of any sort after the switch
For now I left the cap at 5 MB. I planned to make a follow-up PR removing
Good point, I forgot to update them. The benchmarks are not going to be one-to-one though - before we only measured the parse time, while now it measures both parsing and templating (and that's sort of a fundamental part of this change, there's not a way to do one without the other). |
- Add a memory limit for the parser - Abstract most of rendering into a method on `RustdocPage` - Use bytes for parsing to avoid validating UTF8-encoding twice
|
@Kixiron how set are you on having benchmarks? So far I have let html = std::fs::read_to_string("benches/struct.CaptureMatches.html").unwrap();
let page = RustdocPage {
};
let config = unimplemented!();
let conn = Connection::connect(config.database_url.as_str(), postgres::TlsMode::None)?;
let ctx = Context::from_serialize(&page).unwrap();
let templates = TemplateData::new(conn).unwrap();and it shows no signs of slowing down, I just need more and more things to be public. |
Co-authored-by: Chase Wilson <[email protected]>
|
Benches don't matter a ton, I can follow-up with them if need be |
- Raise size limit from 5 MB to 50 MB - Use DOCSRS_MAX_PARSE_MEMORY to configure the max memory, defaulting to 350 MB
|
I also raised the default HTML size limit from 5 MB to 50 MB. Since I tested on a 300 MB file this shouldn't give the prod server any problems. |
|
@jyn514 If understand the context correctly then 5Mb should be enough. Lol-html requires to allocate memory only for really long tags (without content, just start tag tokens). So if you don't have/don't plan to have start tags longer than 5Mb than it should be more than enough for the observable future. (just in case: increasing the buffer size doesn't boost performance) |
Wait, did I read that right? Lol-html will only allocate as much memory as the size of the start tag, even for multi-megabyte files? That's amazing! |
|
@jyn514 yep, it's a streaming parser, so we allocate as less as possible |
|
Switched the limit to 5 MB and it still loaded the 300 MB file fine 🎉 |
This comment has been minimized.
This comment has been minimized.
|
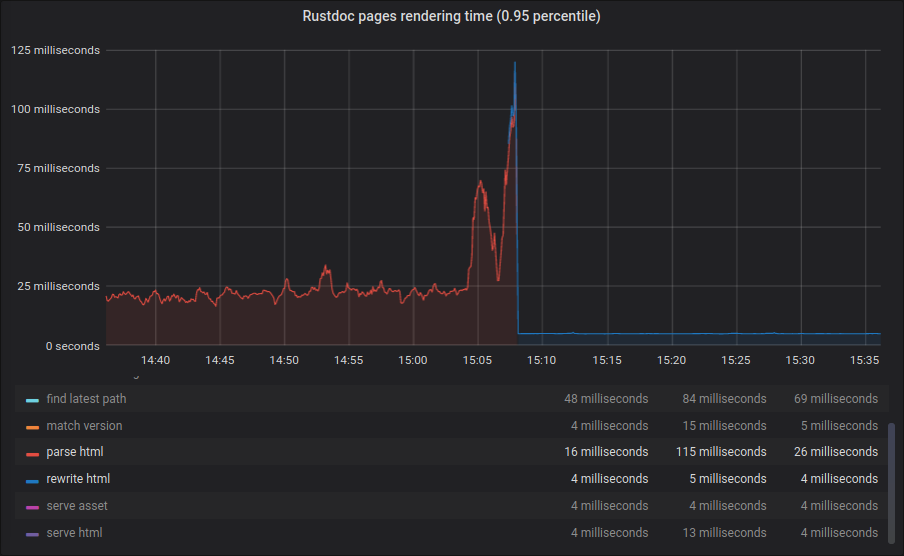
Aha, I was looking at the wrong screen! Those are some nice numbers :D
|


|
@jyn514 btw, I believe you can push the memory limit even further to 3-5Kb, I believe in your case that should be enough |
Closes #876
My styles haven't been working since ~forever, if someone else could check this looks right that would be great. However this looks approximately the same before and after to me.
Ideas for testing this are also welcome - the previous tests were only testing the parsing, not the rendered code, so they're not very useful here.
Before:
After:
r? @Kixiron
cc @nataliescottdavidson