CSHARP-2450: Reduce locking costs in BsonSerializer #482
Conversation
…ashSet<T> protected by a ReaderWriterLockSlim to a ConcurrentDictionary<K,V> outside the ReaderWriterLockSlim.
| @@ -41,7 +42,7 @@ public static class BsonSerializer | |||
| private static HashSet<Type> __discriminatedTypes = new HashSet<Type>(); | |||
| private static BsonSerializerRegistry __serializerRegistry; | |||
| private static TypeMappingSerializationProvider __typeMappingSerializationProvider; | |||
| private static HashSet<Type> __typesWithRegisteredKnownTypes = new HashSet<Type>(); | |||
| private static ConcurrentDictionary<Type, Type> __typesWithRegisteredKnownTypes = new ConcurrentDictionary<Type, Type>(); | |||
There was a problem hiding this comment.
Are any of the other dictionary lookup hot paths (e.g. __discriminatorConventions)? If so, can we change any of them to ConcurrentDictionary?
There was a problem hiding this comment.
There certainly still is __discriminatedTypes which is used in LookupActualType (so damn hot path...). This is something I tackled in #347 which also contains this screenshot of a profiling session that seems to indicate that the remaining locking in LookupActualType would be worth getting rid of:
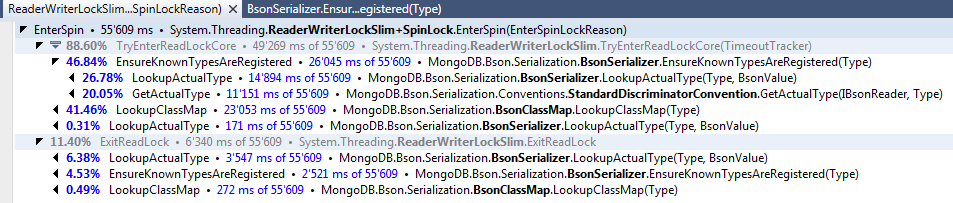
There was a problem hiding this comment.
Agreed. This is still something that we want to take a closer look at. Since the first real work done in LookupActualType is a call to EnsureKnownTypesAreRegistered (this PR), my desire is to get eyes and agreement on this PR - to ensure that it is correct and I didn't miss any threading edge cases - and then rebase PR#347 on top of this so we can get some accurate performance metrics.
Really appreciating the feedback and collaboration on these issues. As well as your patience as it has taken awhile to find time to really dig in and understand the performance and threading implications.
| } | ||
|
|
||
| __configLock.EnterWriteLock(); | ||
| try | ||
| { | ||
| if (!__typesWithRegisteredKnownTypes.Contains(nominalType)) | ||
| if (!__typesWithRegisteredKnownTypes.ContainsKey(nominalType)) |
There was a problem hiding this comment.
Nit: Consider using GetOrAdd instead of the if-ContainsKey-assignment sequence as this will cause two lookups.
There was a problem hiding this comment.
Thank you for the feeback!
GetOrAdd(TKey key, Func<TKey,TValue> valueFactory) internally performs multiple lookups. First to determine if the key is present and then after executing valueFactory but prior to inserting into the collection. If the value is not present in the collection, GetOrAdd will perform two lookups and the current ContainsKey/[]=value does the same. If the value is already present, both only perform a single lookup. Testing out both implementations I see the same performance numbers.
I will add a comment to __typesWithRegisteredKnownTypes[nominalType] = nominalType; noting that it must be performed as the last step to ensure that other threads don't see partially initialized types.
There was a problem hiding this comment.
You're right about the actual lookups, of course. I was thinking about the GetHashCode() calls of which you'd be saving one but, in this case, they're not costly so let's ignore that. It's just a standard thing that I constantly tell my devs: "Always use GetOrAdd instead of the other sequence!"... ;)
In fact, I had originally been coming from suggesting the use of TryAdd() which should have saved the lookups but that didn't work as there's additional work to be done inside the if branch and it needs to happen before the dictionary insert... Anyway, that code is very ok the way it is now, I suppose.
|
Thanks for looking into this and thanks for the kudos. I'm super excited to see the final effect of this once it's been released. Two small remarks:
|
Absolutely agreed. The effect is stronger with more cores and more contention on these locks. I ran with between 4 and 64 threads, but settled on 8 to maximize the concurrency while minimizing the CPU context switching. (My test machine has 16 hyper-threaded cores, which translates into 8 physical cores.) I should also note that this test was intentionally written as a worst-case scenario maximizing contention on these data structures. I did this by keeping the serialized class as small as possible to minimize time deserializing values from BSON into C# properties by only having an
I tried a variety of data structures including |
|
Full Evergreen run across all variants and tasks started to increase our confidence that we are not breaking anything with these changes. Note that the Evergreen results are only visible internally. Thanks for reminding me, @BorisDog. |
You'd be surprised to see our "real-world" scenario. ;) We're using the driver to do a ton of in-memory de-/serialization stuff, e.g. when we send things across the wire to our fat client and receive it on the other end or to parallelize serialization upfront before writing in a single thread to MongoDB. So there's by far not always an I/O-limited database and network sitting at the other end. You might argue that this is not the primary objective of the driver and that's certainly correct. But I am pretty certain that we'll be taking the achieved performance gains home with a smile - more or less the way you measured them! |
There was a problem hiding this comment.
LGTM
What I like about this PR compared to earlier PRs is that as far as I can tell it totally preserves the semantics of a single write lock controlling access to ALL serialization configuration options.
Since the only thing that is different is switching from a HashSet<Type> to a ConcurrentDictionary<Type, Type> (acting as as set) everything should behave exactly the same as before.
…ashSet<T> protected by a ReaderWriterLockSlim to a ConcurrentDictionary<K,V> outside the ReaderWriterLockSlim. (#482)
CSHARP-2450: Improved deserialization performance by switching from
HashSet<T>protected by aReaderWriterLockSlimto aConcurrentDictionary<K,V>outside theReaderWriterLockSlim.The following PR is based heavily on work done by @dnickless in PR#433. I analyzed his changes to determine the origin of the observed 5-10% performance improvement and realized that it was not due to a change in data structure for the registration check but due to reduced locking in the hot deserialization path, notably
StandardDiscriminatorConvention.GetActualType, which callsBsonSerializer.EnsureKnownTypesAreRegistered. By changing__typesWithRegisteredKnownTypesto aConcurrentDictionary<Type, Type>(instead of aHashSet<Type>), I was able to move the registration check outside theReaderWriterLockSlim__config. The following deserialization test shows a 46% performance improvement in this test case. The class being deserialized simply contains anIdfield to magnify the impact of the class registration lookup by minimizing the time spent actually deserializing the data. More complex classes still show a significant improvement though not as dramatic. (e.g. ~36% for a class with an Id and 3 string fields.)To reproduce the results, replace
tests/MongoDB.Driver.TestConsoleApplication/Program.cswith the following code:You can then run the test code via the following bash script using both
masterandcsharp2450branches to observe the performance improvement:I'm cautiously optimistic that I haven't missed any multi-threaded subtlety that precludes this optimization in our serialization code. I look forward to your feedback and thoughts on this improvement. Big props to @dnickless on drawing our attention to the potential improvement and prototyping these changes.